Del ‘método ROPA’ a la ‘maternidad en solitario’: el discurso traducido de las páginas web sobre reproducción asistida1
From the ‘ROPA method’ to ‘single motherhood’: the translated discourse of assisted reproduction technology websites
Gianluca Pontrandolfo2, Università degli Studi di Trieste
Chiara Sarni3, Università degli Studi di Trieste
The Journal of Specialised Translation 44 (2025), 188-216
https://doi.org/10.26034/cm.jostrans.2025.8475

ABSTRACT
The paper offers a corpus-assisted critical discourse study of translated websites on assisted reproduction technology. After building a bilingual (Spanish-Italian) parallel corpus of webpages of Spanish assisted reproduction technology centres and institutes and a monolingual (Italian) reference corpus made of original texts belonging to the same discursive cybergenre, the study aims at exploring three key elements: the linguistic and multimodal sexism employed when describing the subjects involved and its propagation and amplification through translation; the possible impact of translation on the Italian discourse used in this specialised field and the powerful role of translation as a potential disseminator of new discourses on motherhood; the identification of terms that pose translation challenges by referring to concepts related to techniques that are not regulated in Italy. The results allow to detect the existing asymmetries between Spain and Italy when it comes to accessing fertility treatments and reveal interesting traces of the linguistic contact between the two languages and cultures.
KEYWORDS
Webpages, Spanish, Italian, translated discourse, assisted reproduction technology, corpus linguistics, sexism, gender.
RESUMEN
El trabajo propone un análisis crítico del discurso traducido asistido por corpus de páginas web sobre reproducción asistida. Tras compilar un corpus bilingüe (español-italiano) paralelo de páginas web de centros e institutos españoles de reproducción humana asistida y un corpus monolingüe (italiano) de referencia compuesto por textos originales pertenecientes al mismo cibergénero discursivo, el estudio se propone explorar tres elementos fundamentales: el sexismo lingüístico y multimodal empleado a la hora de describir los sujetos involucrados y su propagación y amplificación a través de la traducción; el posible impacto de la traducción en la definición de un italiano de especialidad traducido y el potente papel de la traducción como potencial difusor de nuevos discursos sobre maternidad; los retos a la hora de traducir términos que definen procedimientos que no existen en el horizonte cognitivo y legislativo italiano. Los resultados permiten detectar las asimetrías existentes entre España e Italia a la hora de acceder a los tratamientos de fertilidad y desvelan interesantes huellas del contacto lingüístico entre las dos lenguas y las dos culturas.
PALABRAS CLAVE
Páginas web, español, italiano, discurso traducido, reproducción asistida, lingüística de corpus, sexismo, género.
1. Introducción
El turismo de salud y, en particular, el turismo reproductivo (o turismo de fertilidad), que consiste en el desplazamiento a países extranjeros para recibir determinados tratamientos de fertilidad y reproducción asistida, ha convertido a España en una de las ‘mecas’ de la Unión Europea, con casi 700 millones de euros de ingresos cada año. Un gran porcentaje de turistas sanitarios que solicitan estos servicios procede de Italia. Según los datos del Registro Nacional de Actividad publicados por la Sociedad Española de Fertilidad (SEF) y el Ministerio de Sanidad, de los 12 7420 ciclos de fecundación in vitro (FIV) realizados en España en 2020, 12 171 eran de pacientes que procedían del extranjero, la mayoría de Francia e Italia4.
Esto se debe también a distintas limitaciones que Italia pone a las personas con deseos reproductivos que solo pueden recurrir a la reproducción asistida en determinados casos regulados por la Legge 19 febbraio 2004, n. 40 Norme in materia di procreazione medicalmente assistita frente al alcance mucho más permisivo de la Ley 14/2006 sobre técnicas de reproducción humana asistida5. La comparación de las técnicas de reproducción asistida (RA) permitidas en España e Italia dibuja un panorama caracterizado por muchas asimetrías, cuya descripción detallada excede las finalidades del presente trabajo. En efecto, si bien la mayoría de las técnicas existen en ambos países (entre las más comunes, la inseminación artificial, la Fecundación in vitro (FIV), la microinyección espermática (ICSI), la donación de óvulos, la adopción de embriones, la doble donación de gametos), el acceso que tienen las personas y las parejas en ambos países es muy diferente. En Italia, por ejemplo, solo las parejas de sexo diferente, conyugadas o parejas de hecho, pueden acceder a estas técnicas; en España, en cambio, también las personas solteras y las parejas homosexuales pueden acceder a la RA, situación que introduce en el horizonte cognitivo y legislativo español los conceptos de ‘maternidad compartida’ (a través del método ROPA, ‘Recepción de Ovocitos de la Pareja’, técnica que permite a una pareja de dos mujeres que una sea la madre genética al aportar el óvulo y la otra la madre biológica, al gestar en su vientre al bebé) y de ‘maternidad en solitario’ (la maternidad de una mujer ‘soltera por elección’), que se mencionan en el título del presente artículo.
Sin entrar en los detalles legislativos, sociales e ideológicos de ambos países, lo que es cierto es que el tema de la RA despierta cierto interés para los estudios discursivos y traductológicos no solamente porque se sitúa en la encrucijada de distintos ámbitos sectoriales (medicina, bioética, derecho, sociología/antropología, estudios de género) y representa por tanto un ejemplo paradigmático de interdisciplinaridad en los discursos de especialidad (Calvi, 2023), sino también por sus fascinantes implicaciones para la traducción, que desempeña un papel crucial a la hora de proporcionar información a las personas o parejas italianas que quieran viajar a España para someterse a determinados tratamientos no previstos en Italia. El ingente flujo de turistas italianos/as que viajan a España por estas razones justifica la presencia capilar de páginas web de centros e institutos españoles de reproducción humana asistida traducidas al italiano, lo que representa un observatorio privilegiado desde el cual estudiar determinadas dinámicas traductoras y, por tanto, una oportunidad de investigación sumamente interesante.
La revolución que supuso la llegada de la lingüística de corpus para los Estudios de Traducción (Corpus-based Translation Studies, CBTS) posibilitó, desde los principios del siglo XXI, el estudio empírico de la traducción y de la lengua traducida. Nociones como ‘tercer código’ (Frawley, 1984), ‘translationese’ (Gellerstam, 1986), ‘universales de la traducción’ (Baker, 1993; Laviosa, 2001; Corpas Pastor, 2008), ‘regularidades’ o ‘leyes’ (Toury, 1995) (para una revisión crítica, véase Jiménez Crespo, 2023) remiten a todos aquellos rasgos lingüísticos de la lengua traducida que se diferencian, en cuanto a frecuencia y distribución, de la lengua no traducida. Se trata de tendencias, como el hecho de que los textos traducidos sean más simples y menos ambiguos, más explícitos, más convencionales y estandarizados, en comparación con los textos originales, que bien se pueden investigar mediante la lingüística de corpus y, en particular, a través de corpus comparables, que cotejen textos traducidos y textos no traducidos/originales. Estas diferencias estructurales se pueden interpretar, por un lado, como fenómeno negativo (de ahí el término despectivo ‘translationese’ o ‘traduttese’ en italiano, cf. Ondelli, 2022, pp. 19–20, utilizados a menudo con finalidades irónicas), a saber, errores o calcos debidos a la interferencia lingüística que son claramente el resultado de una mala transposición a la lengua de llegada, por el otro, como fenómeno neutro o hasta positivo (véase Cardinaletti, 2005, pp. 76–77), es decir, huellas de un contacto fructuoso entre lengua de origen y lengua de llegada que produce innovación lingüística y cultural (véase también Malamatidou, 2016).
Estos fenómenos de hibridación discursiva abren una fascinante ventana sobre la caracterización de la lengua traducida (traducción como producto) y las operaciones hermenéuticas de transposición lingüística y cultural (traducción como proceso) que el presente estudio se propone investigar no solamente desde la perspectiva de los estudios de la traducción guiados por corpus, sino también a través del análisis crítico del discurso enfocado desde una perspectiva de género y multimodal. Tras caracterizar desde el punto de vista lexicométrico la lengua (italiana) traducida sobre reproducción asistida, las preguntas de investigación que guían nuestro estudio son las siguientes:
¿Cuál es el papel de la traducción a la hora de limitar o amplificar el sexismo lingüístico y qué implicaciones tiene para el uso de un lenguaje inclusivo y no discriminatorio?
¿Es posible detectar huellas en el producto de traducción que revelan prejuicios ideológicos o construcciones discursivas estereotipadas/sexistas?
¿Cuál es el impacto de la traducción (español-italiano) de las páginas web que describen las técnicas de RA y de las asimetrías legislativas entre España e Italia en el discurso traducido sobre fertilidad y maternidad?
El artículo se compone de cuatro apartados además de esta introducción que contextualiza el estudio: en §2 presentamos la metodología empleada y los corpus de estudio; en §3 realizamos un análisis preliminar lexicométrico del discurso traducido sobre reproducción asistida; en §4 proporcionamos una pincelada de resultados desde la perspectiva del sexismo lingüístico (§4.1) y multimodal (§4.2), los retos de traducción relacionados con la inexistencia de técnicas de RA en Italia (§4.3) y el impacto de la traducción y del discurso traducido en la disponibilidad léxica del italiano de la reproducción asistida (§4.4); en §5 esbozamos algunas consideraciones finales y señalamos algunas pistas futuras de investigación.
2. Material y metodología
Desde el punto de vista metodológico, la investigación que se lleva a cabo combina la lingüística de corpus y el análisis del discurso traducido (Baker, 1993; Corpas Pastor, 2008; Laviosa, 2012), empleando tanto el enfoque de corte deductivo (corpus-driven) como el de corte inductivo (corpus-based) (Tognini-Bonelli, 2001). A estos efectos, se ha recopilado a través del programa Sketch Engine (Kilgarriff y otros, 2004) un corpus bilingüe paralelo ES/IT_PMA de páginas web de centros e institutos españoles de reproducción humana asistida que prestan sus servicios también a un público italiano y, por lo tanto, cuyos sitios web están traducidos al italiano, y un corpus monolingüe de referencia PMA_ITALIA con vistas a comparar los textos traducidos con textos originales no traducidos y apreciar sus diferencias.
La selección de los institutos de cuyas páginas web descargar los textos se ha efectuado consultando los listados oficiales de centros autorizados por el gobierno, español o italiano, dependiendo del corpus, es decir registros que recogen y proporcionan información sobre las instituciones médicas, públicas o privadas, y su prestación de servicios. En concreto, para el corpus paralelo se ha consultado el ‘Registro de centros y servicios de reproducción humana asistida’6, mientras que por lo que se refiere al corpus monolingüe italiano el ‘Registro Nazionale della Procreazione Medicalmente Assistita’7. El criterio de selección de los centros de RA incluidos en los dos registros mencionados ha sido la presencia de un sitio web del instituto y su traducción al italiano. En total, los centros privados que han cumplido con los requisitos de selección han sido 24 italianos y 29 españoles (véase la sección final Páginas web). Además, con miras a ajustar los textos considerados a los objetivos de la investigación se han tomado en cuenta exclusivamente las secciones de las páginas web de las clínicas relativas a ‘técnicas’, ‘tratamientos’, '‘donación de óvulos/semen/gametos/embriones’, ‘pruebas diagnósticas’, ‘preservación de la fertilidad’ y ‘unidades de alta complejidad’, consideradas especialmente relevantes para nuestro estudio.
Los textos se han descargado a través del programa BootCat (Baroni & Bernardini, 2004) y la alineación del corpus paralelo se ha efectuado manualmente. Al tratarse de sitios web, se ha necesitado una gran intervención manual para eliminar los caracteres extraños, saltos de líneas, símbolos, referencias a JavaScript, cookies, etc. De hecho, las fases de alineación y limpieza —que podrían considerarse como el reflejo directo e inmediato de los numerosos escollos que suelen presentarse durante la recopilación de corpus paralelos (Leiva Rojo, 2018)— han planteado muchos problemas que pueden atribuirse a la dicotomía localización-traducción (para profundizar véanse, entre otros, Jiménez-Crespo, 2013; Sandrini, 2005, 2008) y que han permitido esbozar algunas reflexiones preliminares en cuanto a la diferencia de técnicas y tratamientos que suelen efectuarse en España e Italia (cf. §4.3). A este respecto, es importante destacar que en muchos casos algunos segmentos en lengua original (español) o en la lengua meta (italiano) se han eliminado integralmente del corpus paralelo porque (a) algunos centros facilitaban el acceso de los/las pacientes italianos/as a sus tratamientos, pero la traducción del sitio no siempre incluía todas las secciones relativas; (b) a veces, en las páginas web localizadas al italiano, se había añadido información no presente en los textos origen, por ejemplo datos sobre la legislación española o italiana o la posibilidad de organizar entrevistas iniciales en línea para pacientes extranjeros.
Como la compilación del corpus paralelo ha implicado la eliminación (del corpus ES_PMA) o integración (en el corpus IT_PMA) de varios segmentos, se ha decidido crear otros dos corpus de control: un corpus monolingüe ES_PMA_ext que recopila los textos integrales de los centros de RA españoles seleccionados, y un corpus monolingüe italiano IT_PMA_ext, que contiene, de forma especular, los textos integrales traducidos del español disponibles en las páginas web italianas y, por ende, recoge también información adicional añadida para el público italiano.
La Tabla 1 resume la composición de los corpus con los datos extraídos de Sketch Engine.
| ES_PMA | IT_PMA | ES_PMA_ext | IT_PMA_ext | PMA_ITALIA | |
|---|---|---|---|---|---|
| Tokens | 164 488 | 157 918 | 415 748 | 227 998 | 189 093 |
| Words | 146 586 | 140 595 | 369 743 | 202 318 | 167 502 |
| Types (lexicon size: words) | 9313 | 9726 | 12 722 | 12 494 | 10 394 |
| Sentences | 9186 | 9146 | 25 171 | 10 077 | 9867 |
| Lemma | 4919 | 5782 | 6607 | 7918 | 6550 |
Tabla 1. Composición de los corpus objeto de estudio
Como se puede observar de la Tabla 1, los corpus ES_PMA_ext e IT_PMA_ext tienen un tamaño superior en comparación con sus versiones recogidas en el corpus paralelo (ES_PMA, IT_PMA) lo cual apunta a diferencias de contenido, cuyo análisis pormenorizado será objeto de investigaciones futuras, puesto que el foco de este artículo recae principalmente en la comparación entre IT_PMA (discurso traducido) vs. ES_PMA y PMA_ITALIA (discurso original).
Uno de los parámetros más importantes a la hora de compilar un corpus es su representatividad. Para este estudio se han tomado en cuenta los parámetros establecidos por Bolasco (2013), relativos a las denominadas dimensiones útiles, o sea proporción types/token (TTR) inferior al 20% (ES_PMA 7,091%; IT_PMA 7,475%; PMA_ITALIA 6,567%; ES_PMA_ext 3,421%; IT_PMA_ext 6,549%) y porcentaje de hápax inferior al 50% (ES_PMA 44,7%; IT_PMA 45,1%, PMA_ITALIA 43,9%; ES_PMA_ext 41,8%; IT_PMA_ext 45,7%). Los cálculos estadísticos, que han confirmado que los corpus recopilados son representativos, se han efectuado con la herramienta Taltac2 (Bolasco y otros, 1999).
3. Caracterización preliminar del discurso traducido sobre reproducción asistida
El lenguaje médico forma parte del lenguaje científico y técnico con el que comparte las principales características, tales como la universalidad e internacionalización, la objetividad y denotación, la monorreferencialidad, la precisión, la economía y la claridad (Mapelli, 2023). Sin embargo, en el caso de esta investigación, no debe olvidarse que el discurso objeto de este estudio es el de páginas web que, entonces, si bien representa un ejemplo de lenguaje médico, también responde a las necesidades comunicativas dictadas por la Red.
Dentro del vasto panorama de géneros discursivos del lenguaje médico español, el que se analiza a continuación representa un ejemplo de un tipo muy específico y novedoso que ha ido desarrollándose en los últimos veinte años: el llamado cibergénero, es decir, un género [textual] existente en otros medios de comunicación que ha migrado a la Red (Shepherd & Watters, 1998). Y, como destaca Santamaría Pérez (2023, p. 352), en lo que respecta a las páginas web sobre reproducción asistida, “se trata de un discurso híbrido o de un género transfronterizo, ya que, junto a la función informativa, aparecen otras finalidades comunicativas como la apelativa, persuasiva y argumentativa, ya que son clínicas privadas que tienen que convencer a sus destinatarios para que compren su ‘producto’: su técnica o tratamiento” (véase también Pacheco-Baldó, 2023). Cabe precisar que, habiendo fijado como objeto de estudio las secciones de los sitios web relativas a técnicas y tratamientos, se espera que el discurso que se analiza sea de tipo más técnico/divulgativo que ‘comercial’. Por último, la relación entre los/las protagonistas de este contexto comunicativo es de tipo experto-inexperto, es decir, especialistas de la salud y público lego (parejas que quieren formar familia o personas que quieren tener hijos/as).
Una primera visión de conjunto de las características de los corpus, en particular, del corpus de textos traducidos (IT_PMA) y el de textos originales no traducidos (PMA_ITALIA) procede de los datos relativos al type token ratio (TTR) (IT_PMA 7,4%; PMA_ITALIA 6,5%) y al porcentaje de hápax (IT_PMA 45%, PMA_ITALIA 43,9%) que indican que, en línea general, se trata de textos con una muy escasa variedad léxica. Las traducciones suelen ser más pobres con respecto a los textos originales comparables en cuanto al léxico (Ondelli y Viale, 2010, pp. 2–3), pero en este caso los datos apuntarían a lo contrario (aunque la diferencia sea mínima). Otro indicador de la diferencia entre textos traducidos y sus originales es la densidad léxica (véase, por ejemplo, Laviosa, 1998; Ondelli y Viale, 2010). Por lo que atañe a IT_PMA y PMA_ITALIA, los datos son muy similares (total palabras léxicas: IT_PMA 54%; PMA_ITALIA 54%; total palabras gramaticales: IT_PMA 34,40%; PMA_ITALIA 33%) y es interesante apreciar que también en este caso los porcentajes más elevados se registran en el corpus de traducciones.
Siempre con miras a proporcionar información preliminar relativa a la composición de los corpus (IT_PMA y PMA_ITALIA) y, en consecuencia, al discurso traducido sobre reproducción asistida, se propone a continuación un estudio de la frecuencia de las principales categorías gramaticales y de los modos y tiempos verbales detectados por Sketch Engine. En este caso, en aras de exhaustividad, también se incluyen los datos de ES_PMA (el subcorpus con los textos origen de IT_PMA). Tratándose de un estudio que se enmarca en la lingüística de corpus y que, por ende, puede recurrir a datos estadísticos, se ha decidido calcular para las Tablas 2, 3 y 4 el valor de p efectuando la prueba de independencia de chi-cuadrado, lo que ha revelado que las diferencias observadas no se deben al azar y que las variables están relacionadas entre sí, siendo, por tanto, datos estadísticamente significativos.
| ES_PMA | IT_PMA | PMA_ITALIA | |
|---|---|---|---|
| Adjetivos | 7,7% | 9,4% | 10% |
| Conjunciones | 4,5% | 3,8% | 3,7% |
| Artículos | 9,2% | 8,8% | 8% |
| Sustantivos | 26% | 27% | 28% |
| Pronombres | 4,5% | 4,8% | 4,1% |
| Adverbios | 2,9% | 3,2% | 3,3% |
| Verbos | 14% | 14% | 13% |
| Numerales | 1,2% | 1,2% | 1,2% |
| Preposiciones | 16% | 17% | 17% |
| Interjecciones | 0,0012% | 0,00063% | 0 |
| Signos de puntuación | 10% | 10% | 10% |
Tabla 2. Frecuencia relativa de las categorías gramaticales
Como se desprende de la Tabla 2, la distribución de las partes del discurso es bastante homogénea y similar en los tres corpus analizados. Las diferencias más significativas entre ES_PMA e IT_PMA también desde el punto de vista estadístico (o sea, en función de la prueba de independencia de chi-cuadrado) se deben a adjetivos, conjunciones y artículos. Estas desigualdades se deben sin duda a las diferencias intrínsecas de las dos lenguas (español e italiano); de hecho, en este caso IT_PMA y PMA_ITALIA se parecen más entre sí que ES_PMA e IT_PMA. Resultan interesantes las escasas frecuencias de las interjecciones (ES_PMA 0,0012%; IT_PMA 0,00063%; PMA_ITALIA 0) y de los numerales (ES_PMA 1,2%; IT_PMA 1,2%; PMA_ITALIA 1,2%) porque reflejan las características del género textual elegido. Siendo el objeto de estudio exclusivamente las secciones relativas a ‘técnicas’ y ‘tratamientos’, faltan las interjecciones que expresan emociones. Al mismo tiempo, a pesar de tratarse de secciones que expresan desde un punto de vista científico en qué consisten las terapias de RA y lo que conllevan, son textos presentes en la Red que deben ser fácilmente accesibles y comprensibles, por lo tanto, se eliminan los elementos que pueden dificultar la lectura, como los números. Esto se ve confirmado también por los datos antes mencionados sobre la riqueza y densidad léxica que indican que son textos muy sencillos.
| ES_PMA | IT_PMA | PMA_ITALIA | |
|---|---|---|---|
| Indicativo | 5,28% | 5,95 | 5,30% |
| Subjuntivo | 0,60% | 0,42% | 0,33% |
| Condicional | 0,05% | 0,03% | 0,02% |
| Infinitivo | 3,12% | 3% | 3,06% |
| Participio | 2,2% | 2,7% | 2,9% |
| Gerundio | 0,36% | 0,30% | 0,32% |
Tabla 3. Frecuencia relativa de los modos verbales
| ES_PMA | IT_PMA | PMA_ITALIA | ||
|---|---|---|---|---|
| Indicativo | Presente | 4,3% | 4,2% | 3,9% |
| Pretérito perfecto compuesto | 0,23% | 1,1% | 1,1% | |
| Pretérito imperfecto | 0,061% | 0,054% | 0,012% | |
| Pretérito pluscuamperfecto | 0,011% | 0,013% | 0,0037% | |
| Pretérito perfecto simple | 0,1% | 0,026% | 0,0032% | |
| Pretérito anterior | 0,0012% | 0,0013% | 0,00053% | |
| Futuro simple | 0,57% | 0,41% | 0,19% | |
| Futuro perfecto | 0,0091% | 0,15% | 0,092% | |
| Subjuntivo | Presente | 0,52% | 0,34% | 0,27% |
| Pretérito perfecto | 0,034% | 0,056% | 0,055% | |
| Pretérito imperfecto | 0,04% | 0,016% | 0,0079% | |
| Pretérito pluscuamperfecto | 0,003% | 0,0082% | 0,0016% | |
| Condicional | Condicional simple | 0,049% | 0,025% | 0,012% |
| Condicional perfecto | 0,0012% | 0,007% | 0,0032% | |
| Infinitivo | Presente | 3,1% | 3% | 2,8% |
| Compuesto | 0,018% | 0,25% | 0,26% | |
| Participio | Compuesto | 2,2% | 2,7% | 2,9% |
| Gerundio | Presente | 0,36% | 0,3% | 0,32% |
| Compuesto | 0,0012% | 0,00063% | 0,00053% | |
Tabla 4. Frecuencia relativa de los tiempos verbales
Por lo que se refiere al análisis de los modos y tiempos verbales8, como era de esperar, para ambas lenguas, el modo más utilizado es el indicativo y en especial el tiempo presente. Se trata del tiempo propio de las definiciones y enunciados del lenguaje científico y que contribuye a crear el tono de universalidad y atemporalidad de las frases (Mapelli, 2023). Otra diferencia estadísticamente significativa entre textos origen y textos meta atañe a los datos del pretérito perfecto compuesto (ES_PMA 0,23%; IT_PMA 1,1%). Como se aprecia de la Tabla 4, es un tiempo que se utiliza más en italiano. Analizando efectivamente las concordancias de Sketch Engine, se descubre que, en el proceso de traducción, algunos casos de indicativo presente en el texto original se convierten en pretérito perfecto compuesto en el texto de llegada, ajustándose a las convenciones discursivas de la lengua italiana.
Por el contrario, una diferencia estadísticamente significativa entre textos originales no traducidos y traducciones interesa el uso del futuro (simple) de indicativo (IT_PMA 0,41%; PMA_ITALIA 0,19%). Considerando el dato de este tiempo verbal en el subcorpus español (ES_PMA 0,57%), es posible afirmar que, si bien se trata de un tiempo que se emplea poco en las páginas web italianas sobre RA, presenta una frecuencia tan elevada por influencia de la lengua origen. A partir de esta reflexión, un aspecto crucial que puede desprenderse observando las tablas se refiere a las frecuencias del corpus IT_PMA y, por tanto, las características que pueden deducirse de ellas, que se asemejan mucho a las del corpus ES_PMA, salvo los casos que se han señalado anteriormente. Esto se podría atribuir, por un lado, al hecho de que pertenecen al mismo género textual y, por el otro, al posible uso de programas de traducción automática. A este respecto, se detectan errores de puntuación, errores de traducción, repeticiones no justificadas, errores semánticos, falta de revisión, traducciones de escasa calidad, por mencionar algunos.
4. Análisis guiado por corpus
El objetivo principal de este apartado es ofrecer una aproximación al discurso traducido (español-italiano) sobre reproducción asistida haciendo hincapié en tres elementos fundamentales: el sexismo lingüístico empleado a la hora de describir los sujetos involucrados y su propagación y amplificación a través de la traducción (§4.1) y/o de las imágenes (§4.2); la identificación de términos que plantean retos traductológicos puesto que remiten a conceptos relacionados con procedimientos que no se regulan en Italia (§4.3); el impacto de la traducción en la definición de un italiano de especialidad traducido y el potente papel de la traducción como potencial difusor de nuevos discursos sobre maternidad (§4.4).
4.1 La intersección entre sexismo lingüístico y traducción del discurso sobre reproducción asistida
La lengua no es solo un medio de comunicación, sino también la principal herramienta de construcción y clasificación de la realidad. De hecho, según la famosa hipótesis de Sapir-Whorf (Sapir & Lee Whorf, 2017), la lengua condiciona la forma de pensar de las personas que, por tanto, al comunicar, transmiten sus ideas. Es necesario hacer hincapié en la idea de que el lenguaje permite definir su propia posición en el mundo, pero, al mismo tiempo, puede convertirse en un poderoso medio de discriminación con el que no se reconoce o se invisibiliza la existencia de un grupo de personas (cf. Machin & Mayr, 2023, pp. 26–30), como a menudo es el caso de las mujeres. Por consiguiente, cada tipo de texto, o sea, una concretización de la lengua, también desempeña un papel importante en la configuración de la realidad. Apareciendo en la Red y, por tanto, siendo accesibles a un número potencialmente infinito de personas, el papel de los textos objeto de este estudio es igual de importante en la construcción de la visión del mundo. Además, su traducción amplifica la difusión de estos textos y por lo tanto también ejerce un efecto configurador de la realidad. El objetivo de este apartado es esbozar algunas reflexiones preliminares sobre la intersección entre sexismo lingüístico y traducción al italiano del discurso español sobre reproducción asistida. Cabe precisar que con ‘sexismo lingüístico’ (linguistic sexism), término que se usó por primera vez en los años 60–70 en Estados Unidos, se entiende la discriminación de personas a través del uso del lenguaje (véanse, entre otros, Sabatini, 1987; García Meseguer, 1988; Robustelli, 2000; Bengonchea Bartolomé, 2015).
Desde la perspectiva de género se ha publicado mucho sobre reproducción asistida tanto en el contexto español como en el italiano. Los estudios se han centrado en el aspecto jurídico o ideológico de la RA, pero en realidad no son pocos los que se enfocan en el aspecto lingüístico para despertar sensibilidad con respecto a las cuestiones de género. Por ejemplo, Carreras i Goicoechea & Zucchini (2011) han estudiado la presencia del masculino y del femenino en la normativa española e italiana sobre RA, llegando a la conclusión de que es España el país que muestra mayor atención hacia la igualdad de trato lingüístico entre hombres y mujeres. Además, a lo largo de los años en España como en Italia se han elaborado varias directrices con el propósito de frenar el sexismo, como el ‘Manual de Estilo para la redacción de textos científicos y profesionales’ de Fuentes Arderius et al. (s.f.) señalado en Carreras i Goicoechea & Savoca (2014, p. 111). En este último trabajo, el foco de investigación era precisamente la traducción al español de artículos científicos redactados en italiano sobre reproducción asistida. Los resultados de este estudio han permitido subrayar la importancia de sensibilizar al alumnado de traducción relativamente a las cuestiones de género también en textos que, al tener a la mujer como sujeto principal, no parecen plantear estos problemas. Por el contrario, Santamaría Pérez (2023, pp. 348, 368, 269), a través de su investigación acerca de las páginas web de clínicas de RA españolas, ha descubierto que estas constituyen a menudo un hervidero de sexismo: el discurso es patriarcal, la mujer solo es una madre, su cuerpo se reduce a mero recipiente y su esterilidad ‘se mide en términos de valoración escalar negativa’ con respecto a la masculina.
Como señalan Carreras i Goicoechea & Savoca (2014, p. 110), “el sistema gramatical de los idiomas flexivos (como el español y el italiano) es, en unos casos, una de las causas de las tendencias discriminatorias.” A raíz de esta afirmación se realiza a continuación un estudio sobre la traducción de las palabras empleadas para referirse a los sujetos involucrados en la reproducción asistida. Este análisis combina métodos automáticos/cuantitativos con métodos manuales/cualitativos, es decir, en ES_PMA e IT_PMA se ha utilizado la función Concordance de Sketch Engine para aislar automáticamente todos los sustantivos y, de forma manual, se han seleccionado las palabras que se refieren a personas.

Gráfico 1. Datos relativos al género de los sustantivos empleados en ES/IT_PMA
Como se desprende del Gráfico 1, los textos origen en español para referirse a los individuos implicados en los tratamientos de reproducción asistida prefieren usar palabras en femenino o comunes en cuanto al género, mientras que en el italiano traducido priman el masculino y el femenino. Además, puede destacarse que en ES_PMA el femenino es sobrerrepresentado con respecto al género masculino, lo que reflejaría el hecho de que son las mujeres las protagonistas de la RA, como señalaba Santamaría Pérez (2023).
Los individuos protagonistas de las técnicas de RA también son los futuros hijos y las futuras hijas, objeto también de sexismo lingüístico. Si se observan las frecuencias, se nota que se habla más de hijos (45) que de hijas (4) y se recurre al masculino genérico. En el caso de ‘bebé’ (76), que teóricamente podría indicar tanto hijos como hijas, analizando las ocurrencias de Sketch Engine, se observa que siempre se usa en masculino, lo cual se refleja claramente en la traducción al italiano. Las únicas veces en las que se emplea un término femenino por lo que atañe a hijos/as se encuentran en el testimonio de parejas y personas que han beneficiado de los tratamientos de las clínicas y que se encuentran mencionado como discurso referido en las páginas web (Figuras 1 y 2).
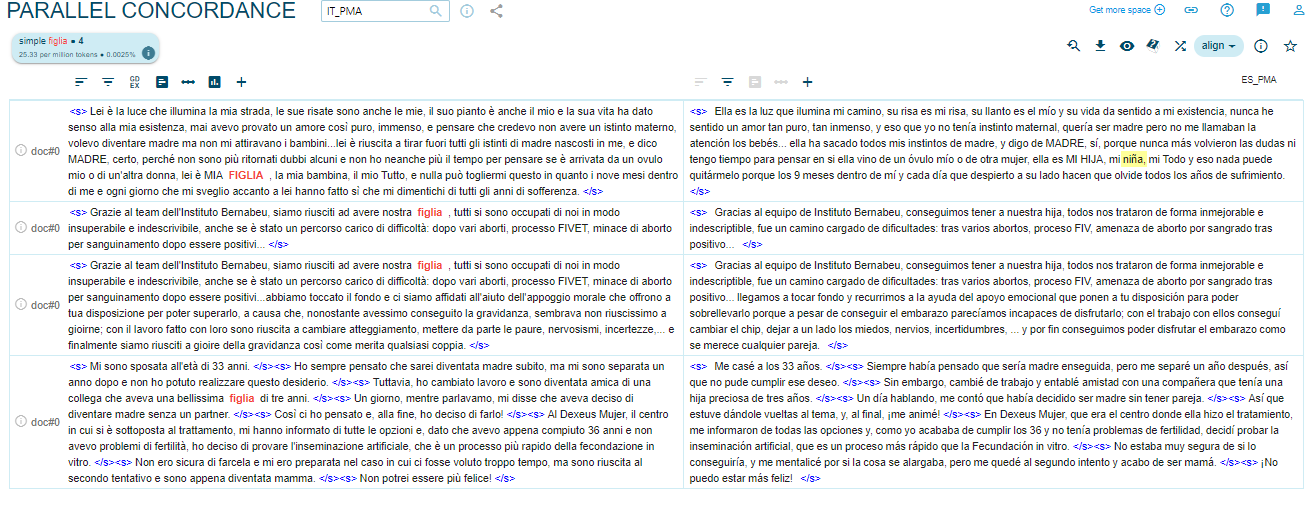
Figura 1. Uso de ‘figlia’ en ES/IT_PMA
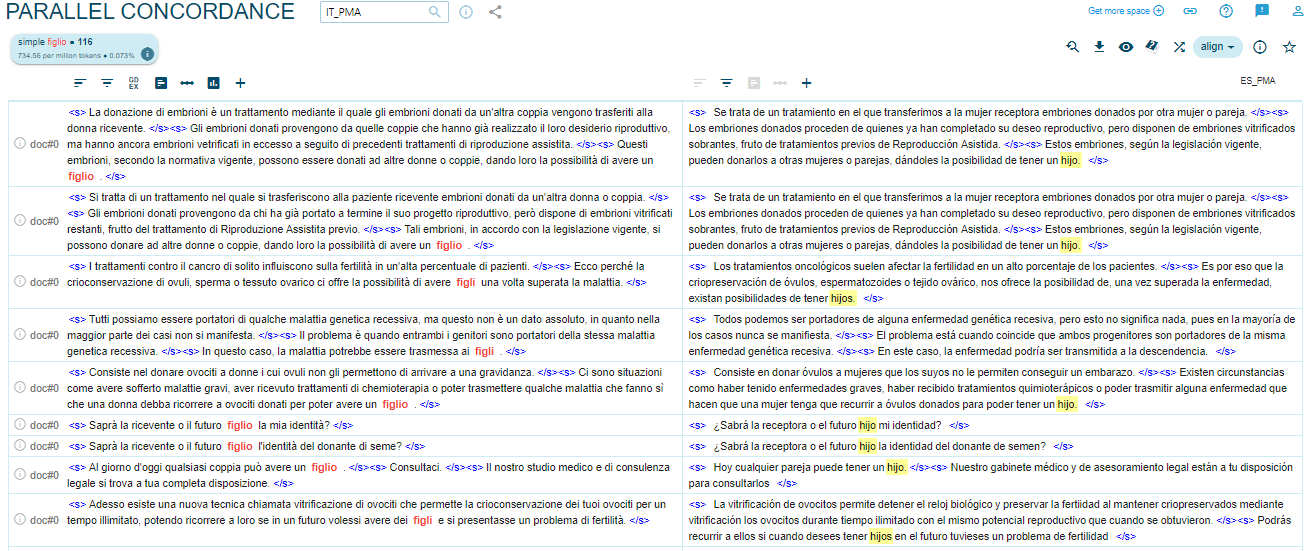
Figura 2. Uso de ‘figlio’ en ES/IT_PMA
Consideraciones interesantes acerca del sexismo lingüístico también pueden proceder del análisis de las palabras de profesiones, cuyos datos se resumen en el Gráfico 2.

Gráfico 2. Géneros de las palabras de profesiones en ES/IT_PMA
El Gráfico 2 muestra claramente que el género más utilizado es el masculino tanto en ES_PMA como en IT_PMA. Destaca nuevamente que los sustantivos comunes en cuanto al género se usan más en español que en italiano. Sin embargo, hay que considerar que esto también se debe al hecho de que algunas de estas se traducen con palabras en masculino en italiano.
Para profundizar en estos sustantivos que cambian de género en la traducción del español al italiano, se ha decidido llevar a cabo un análisis enfocado en las variaciones (o ‘translation shift’) en los textos meta del género empleado en la lengua origen. Se han detectado tres tipos diferentes de cambios de género en traducción: (a) del femenino al masculino (125 casos); (b) del masculino al femenino (16 casos); (c) del ‘neutro’ al masculino genérico (77 casos). Como era de esperar, los cambios cuantitativamente más significativos se han producido en el caso de la transposición del femenino al masculino y del neutro al masculino genérico, lo cual también se ve confirmado por los datos resumidos en los Gráficos 1 y 2. Las palabras afectadas por estos cambios de género son las de profesiones y las comunes en cuanto al género. La única excepción ha sido la palabra ‘receptora’ (131) que en el 13% de los casos se ha traducido en italiano con el masculino ‘il ricevente’ (Figura 3).

Figura 3. Traducción de ‘la receptora’ como ‘il ricevente’ en ES/IT_PMA
Los sustantivos comunes en cuanto al género que han sufrido los cambios más considerables son ‘donante(s)’ y ‘paciente(s)’. Primero, un dato curioso es la traducción ‘donante/i’ (38) ya que en italiano en realidad no se usa tan frecuentemente9, entonces constituiría una traducción poco común del español ‘donante/ovodonante’. De hecho, en el corpus monolingüe de referencia PMA_ITALIA ocurre solo 4 veces (2 en singular, 2 en plural) y procede de sitios de clínicas que, si bien figuran en el Registro nacional italiano, son extranjeras: se puede asumir que se trata a su vez de traducciones, puesto que la palabra de uso equivalente en PMA_ITALIA es ‘donatore/donatrice’. Por lo que se refiere al cambio de género, ‘donante’ (f.) se ha traducido con ‘donatore’ en italiano en el 13,8% de los casos y ‘donantes’ (f.) en el 23,5%; también se registra un 61,9% de casos de transposición del neutro al masculino genérico (donantes > donatori). En cuanto a la traducción de ‘paziente’/’pazienti’, en el corpus se aprecia que, respectivamente en el 14,4% y 9,9% de los casos, ‘la paciente/las pacientes’ se convierten en hombre/s en italiano, como muestra la Figura 4.
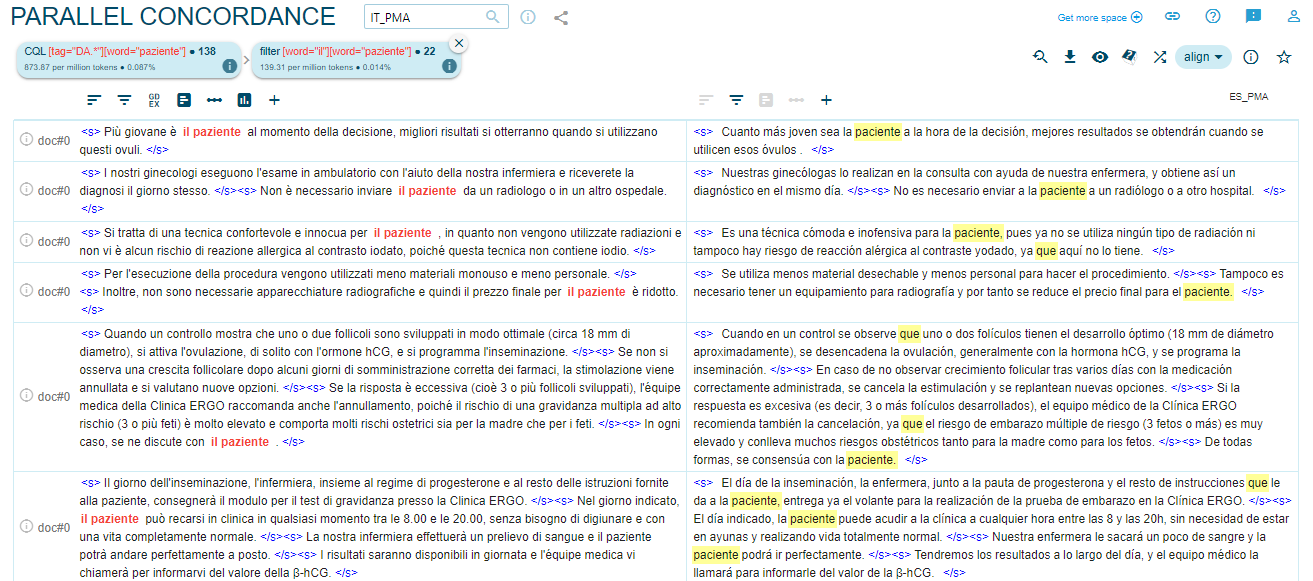
Figura 4. Traducción de ‘paciente’ en ES/IT_PMA
Es curioso señalar que, por ejemplo, en la primera concordancia en la Figura 4 está claro que solo puede tratarse de una mujer, ya que se habla de sus óvulos. Esto podría deberse al empleo de traducción automática y a su ‘male bias’. Como afirman Vanmassenhove y otros (2021, p. 3003), en los sistemas de traducción automática generalmente cualquier género se traduce al masculino (véase también, Rico Pérez & Martínez Pleguezuelos, 2025, p. 258).
Por lo que se refiere a las palabras de profesiones, como se puede desprender del Gráfico 2, predomina el uso del masculino genérico en ambas lenguas objeto de análisis: en la mayoría de los casos, solo se usan las palabras en femenino cuando se refieren a mujeres específicas. Sin embargo, lo que más llama la atención es que incluso los pocos casos de palabras españolas en femenino desaparecen en la traducción sin razón alguna como se aprecia en las Figuras 5, 6, 7 y 810.
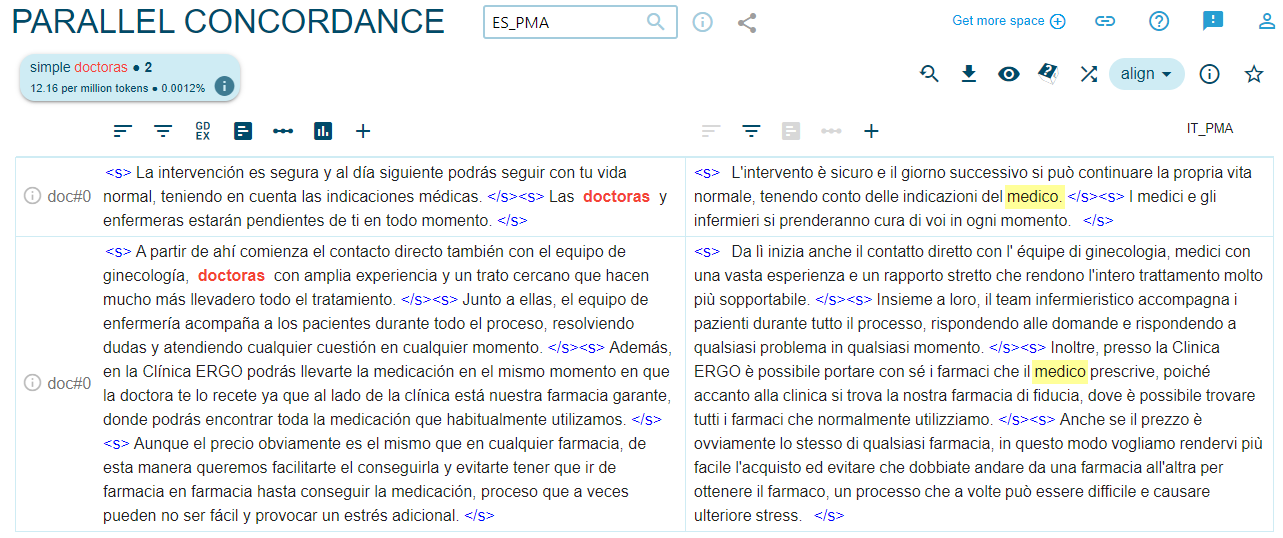
Figura 5. Traducción de ‘doctoras’ en ES/IT_PMA
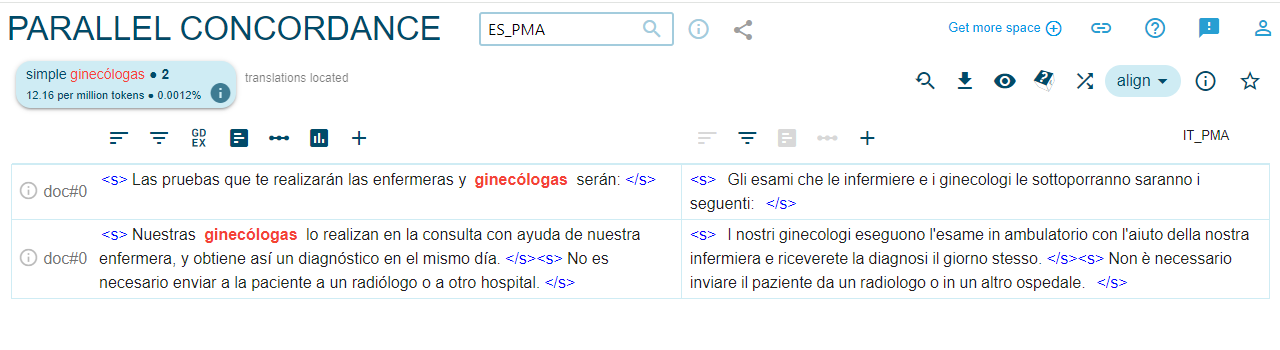
Figura 6. Traducción de ‘ginecólogas’ en ES/IT_PMA
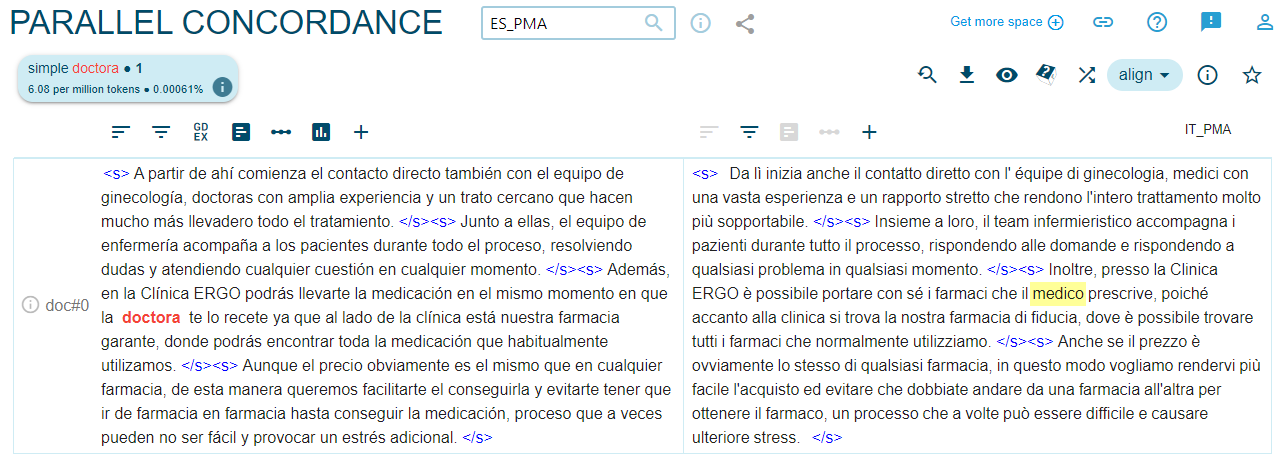
Figura 7. Traducción de ‘doctora’ en ES/IT_PMA
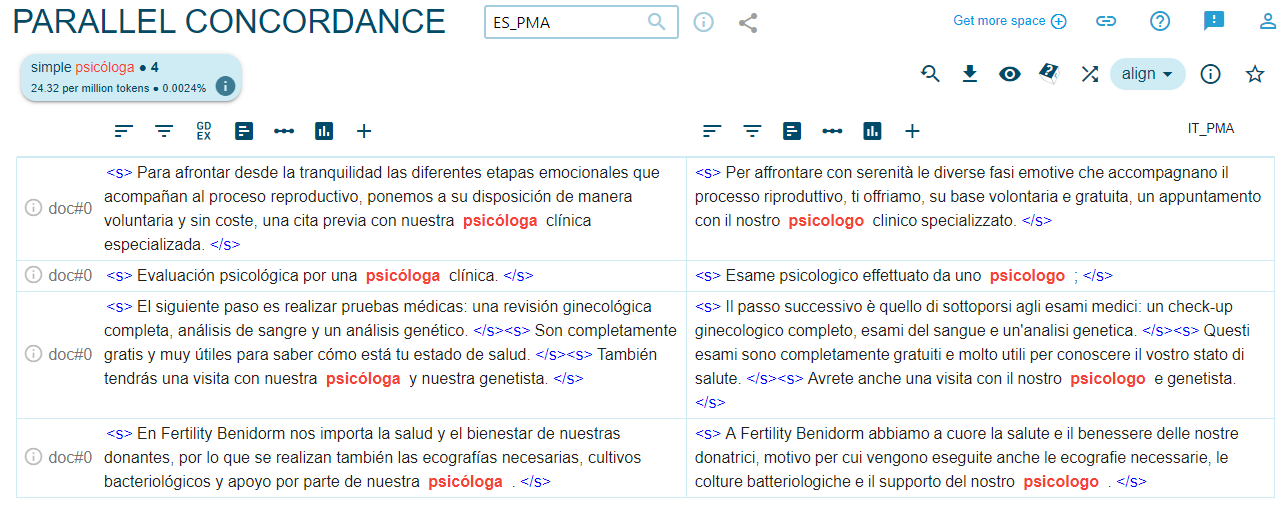
Figura 8. Traducción de ‘psicóloga’ como ‘psicologo’ en ES/IT_PMA
La única profesión en la que no aparecen palabras en masculino en español y aparece en masculino solo dos veces en italiano es ‘enfermera’ (9)/’enfermeras’(6). Se podría pensar en este caso que se repite el estereotipo clásico de la ‘enfermera como mujer’ y el ‘médico como hombre’, lo que también se ve confirmado por los datos (cf. Gráfico 2) y amplificado por la traducción (p. ej. Las pruebas que te realizarán las enfermeras y ginecólogas serán / Gli esami che le infermiere e i ginecologi le sottoporranno saranno i seguenti).También en el caso de las palabras de profesiones se registran cambios del neutro en español al masculino genérico en italiano: por ejemplo, ‘profesionales’ sin ninguna marca de género se traduce como ‘professionisti’ (m.pl.) en el 66,6% de los casos, ‘especialistas’ como ‘specialisti’ (m.pl.) en el 79% de los casos.
Para concluir, este análisis del léxico ha permitido confirmar la presencia de sexismo lingüístico tanto desde el punto de vista de la cantidad de sustantivos en masculino y femenino utilizados para referirse a los sujetos implicados en la reproducción asistida como en lo que respecta a la traducción, que, como confirmaron los porcentajes de cambios, conlleva una propagación del fenómeno en la combinación español-italiano.
4.2 Estereotipos y sesgos de género entre texto e imágenes: una mirada multimodal
Una de las características del cibergénero objeto de investigación en este estudio es, sin duda, la presencia de imágenes y vídeos que acompañan los textos y las descripciones de las técnicas y tratamientos de RA. El objetivo de esta sección es esbozar algunas reflexiones multimodales orientadas a confirmar los resultados obtenidos en §4.1, dejando el análisis multimodal completo y sistemático del corpus objeto de estudio para otros trabajos. El sexismo lingüístico no se vehicula solamente a través de las palabras, como se ha demostrado fehacientemente en §4.1, sino también a través de las elecciones semióticas y de las representaciones visuales de los actores sociales (van Leeuwen 2008; Machin & Mayr, 2023, pp. 108–145). En un discurso caracterizado también por finalidades publicitarias y comerciales, investigar las estrategias de representación de las identidades permite tener otra visión complementaria de los temas analizados.
Sin pretensión de exhaustividad, se presentan tres tendencias principales observadas a partir de un primer análisis crítico del discurso multimodal: 1) la presencia de estereotipos multimodales independientes de la traducción español-italiano; 2) la presencia de desajustes entre texto e imagen que se traducen en un discurso sexista; 3) la presencia de estereotipos multimodales que se amplifican por medio de la traducción.
Por lo que se refiere a la primera categoría, nos referimos a la representación multimodal de las mujeres lesbianas en el ámbito del método ROPA, del hombre donante en contraste con la mujer donante en el caso de la donación de gametos, y de la mujer soltera por elección en el caso de la FIV o ICSI. Muchas de las imágenes que acompañan el texto de las clínicas de RA relativo a la técnica ROPA (re)presentan a las mujeres homosexuales como ‘alternativas’, con el pelo teñido de colores muy llamativos, muchas veces con mujeres de color11. Estas representaciones sesgadas de identidades sexuales que se alejan de las ‘tradicionales’ contribuyen a trasmitir mensajes discriminatorios en los que se cruzan distintos elementos como género, etnias, clase social, orientación sexual, edad, nacionalidad, etc., típicos factores de la interseccionalidad que desembocan, a menudo, en injusticias sociales y discriminaciones.
Otras representaciones estereotipadas emergen, como es previsible, de la figura del donante y de la donante: las finalidades persuasivas de este cibergénero se traducen en imágenes en el que el hombre que dona su esperma se representa como el clásico hombre hermoso y atractivo, mientras que la mujer se representa como (muy) joven, guapa y sana12. Cabe señalar, en línea con las reflexiones planteadas en §4.1, el choque que se observa en algunas páginas entre el texto que titula la sección (en el que se habla de donantes en masculino, ‘i donatori’) y la imagen que representa inequivocablemente a mujeres.
Por lo que concierne a la segunda categoría, los casos más interesantes se refieren al contraste entre el texto y la imagen. Por lo que atañe al método ROPA, por ejemplo, las imágenes solo pueden mostrar a dos mujeres ante especialistas de RA, puesto que se trata de un tratamiento para mujeres lesbianas. Con todo, en algunos casos se observa un choque entre las imágenes y el texto que las acompaña, donde se sigue hablando refiriéndose en masculino (p. ej. nuestro objetivo es cumplir con los sueños de nuestros pacientes / il nostro obiettivo è realizzare i sogni dei nostri pazienti)13, en línea con los cambios de género ya observados en §4.1. En muchos de estos textos el término ‘cónyuge’ no concuerda con el género, que no puede que ser femenino en el caso de la maternidad compartida por dos mujeres, y tanto en los textos originales como en los traducidos se encuentra el masculino (el cónyuge/il coniuge), lo cual crea un evidente efecto de extrañamiento en quien lea estas páginas. Emblemáticos son también los casos en los que se representa al equipo de las clínicas compuestos en su mayoría por mujeres con ‘medici’ (médicos en masculino)14.
Por último, en la tercera categoría se encuentran casos que ponen de manifiesto los potenciales riesgos de discriminación en el discurso traducido sobre RA sobre todo cuando se produce una disparidad y una falta de correspondencia entre el discurso original denotativo en español y el discurso traducido connotativo en italiano (sobre el contraste lingüístico y semiótico entre denotación vs. connotación véase Machin & Mayr, 2023, pp. 67–68). Ejemplos paradigmáticos de una amplificación del sexismo discursivo a través de la traducción son aquellos en los que la sección dedicada a la técnica ROPA —no permitida en Italia— se localiza en italiano con el connotativo ‘parejas homosexuales’ con una previsible eliminación de la imagen, desplazando el foco del texto origen en la técnica RA a los sujetos involucrados en el texto meta15.
Hay también otros ejemplos interesantes relativos a la representación discursiva y multimodal de la maternidad en solitario, como el cambio de la denotación del texto origen (‘Maternidad en solitario por elección’) a la connotación del texto meta (‘La maternità single, una decisione coraggiosa’ / La maternidad en solitario, una decisión valiente) con textos que añaden capas sexistas al discurso sobre las mujeres solteras: una mujer que, si bien pasan los años, no pierde el deseo de formar una familia; una mujer con estudios, que ha alcanzado una posición profesional y social relevante, que es independiente económicamente para poder dar todo lo mejor a su bebé, que ha decidido conocerse más, crecer e incluso viajar [sic] hasta convertirse en la mujer que es ahora16.
Un último ejemplo emblemático se da en relación a otra técnica no permitida en Italia (la fecundación in vitro para personas trans). En la adaptación al público italiano, se encuentran casos de clínicas que añaden porciones de textos, ausentes en la página web original, en las que se invitan, por ejemplo, a los hombres trans [sic] a aprovechar una promoción especial y un descuento económico para la vitrificación de los óvulos [sic] 17. La circulación de estos recursos semióticos y la trasmisión de estos discursos sesgados —también por medio de la traducción— pueden tener efectos perjudiciales y una traducción infiel al original puede contribuir a amplificar el sexismo con repercusiones en nuestra vida social.
4.3 Traducir las ausencias: una aproximación basada en Keywords
Las técnicas de la lingüística de corpus son muy útiles para investigar los rasgos diferenciales entre textos traducidos y textos originales ya que permiten desvelar el comportamiento traductor mostrando ciertas tendencias o regularidades de la lengua traducida (cf. Corpas Pastor, 2008, p. 99). En el caso que nos ocupa, la comparación entre el subcorpus de textos traducidos (IT_PMA) y el subcorpus de textos originales (PMA_ITALIA) permite detectar ejemplos interesantes de influencia de la lengua y cultura de origen (español/España) en la lengua y cultura meta (italiano/Italia) y una de las técnicas de corpus más útil para esta finalidad es la función Keywords (palabras clave).
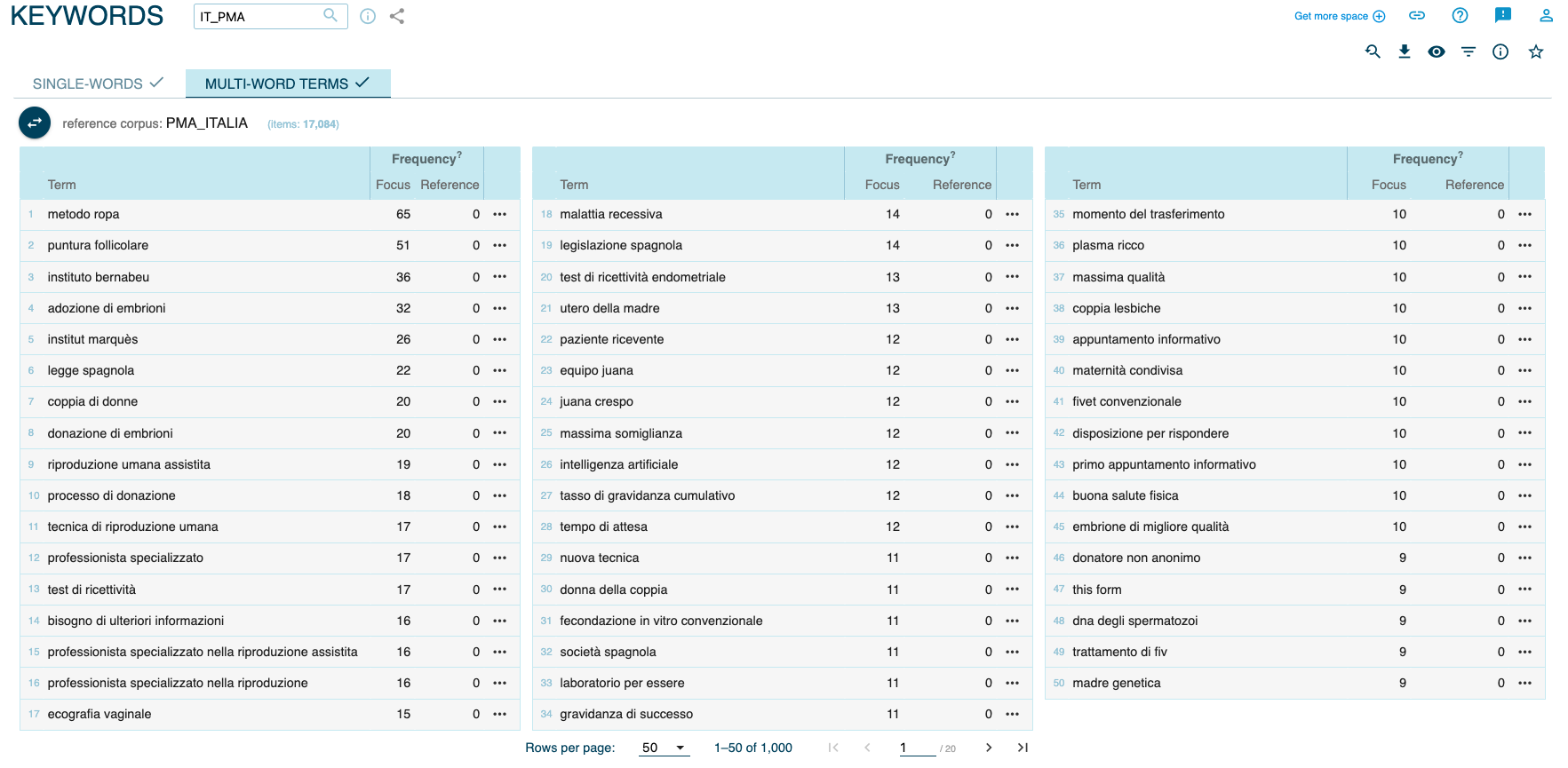
Figura 9. Keywords (IT_PMA vs. PMA_ITALIA)
La Figura 9 presenta las primeras 50 palabras clave obtenidas mediante la comparación entre IT_PMA (focus corpus) y PMA_ITALIA (reference corpus). Además de las inevitables referencias a España y a la legislación española (legge spagnola (22), legislazione spagnola (14), società spagnola [di Fertilità] (11)), que se deben a la necesitad de señalar las diferencias entre la normativa española e italiana en materia de RA para el público italiano que lee las páginas web, destaca la alta frecuencia de términos como método ropa (65), en primera posición, que se relaciona con la técnica de reproducción asistida prohibida en Italia y que tiene que ver con parejas de mujeres (coppia di donne (20), donna della coppia (11), coppie lesbiche (10)) que optan por una maternidad compartida (maternità condivisa (10)). Como en Italia el acceso a la reproducción médicamente asistida está prohibido a las mujeres solteras y homosexuales, no hay ninguna referencia a esta técnica en el corpus de textos originales (PMA_ITALIA) y solo se encuentra en el corpus de textos traducidos, en el que se convierte en un verdadero neologismo, fruto de la transferencia al italiano de un procedimiento que no existe en el horizonte conceptual y legislativo italiano.
Es interesante observar cómo una situación parecida se da en el caso de las mujeres solteras que opten por la reproducción asistida: términos como maternidad en solitario (26 ES_PMA_ext, 14 ES_PMA), mujeres/madres solteras (33 ES_PMA_ext, 26 ES_PMA) o solas (3 ES_PMA_ext, 4 ES_PMA) o madre soltera/maternidad por elección (8 ES_PMA_ext, 4 ES_PMA) se encuentran en el corpus italiano traducido (IT_PMA) como evidentes calcos del español (single (40), madri/maternità da sole (8)), mientras que en el corpus original las únicas ocurrencias de single (7 PMA_ITALIA) se refieren a la imposibilidad de llevar a cabo este procedimiento en Italia (cf. Figura 10) o a la posibilidad de congelar embriones para futuros tratamientos de RA.
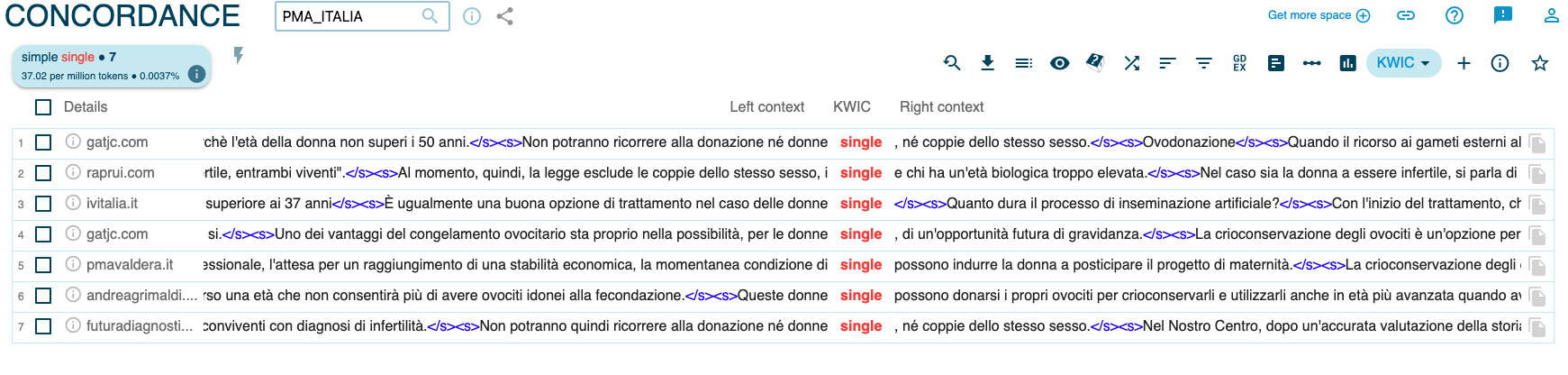
Figura 10. Single en PMA_ITALIA
Dos palabras compuestas clave interesantes son adozione di embrioni (32) y donazione di embrioni (20) que no se usan en el corpus de referencia italiano (PMA_ITALIA). Se trata, en ambos casos, de una técnica heteróloga denominada embrioadopción (o adopción de embriones donados) con la que se transfiere a la paciente un embrión donado y previamente vitrificado.
Por lo que se refiere a la donación de gametos, y no específicamente de embriones (gametos femeninos), cabe señalar que la Ley 14/2006, de 26 de mayo, sobre técnicas de reproducción humana asistida (art. 5) autoriza la donación de gametos y preembriones de forma gratuita, mientras que en Italia se puede recurrir a la denominada fecundación heteróloga solamente en algunos casos específicos (situaciones de infertilidad/esterilidad comprobada de uno a ambos miembros de la pareja que les impide emplear gametos propios) gracias a la sentencia 162/2014 de la Corte Costituzionale, que ha levantado la prohibición (establecida por la Legge 40/2004) de la donación de gametos procedentes de donantes ajenos a la pareja. No sorprende, por tanto, la ausencia del término donazione di embrioni en el corpus de referencia PMA_ITALIA, donde se emplean términos más generales como gameti (donazione di gameti (16)), seguido por donazione di seme (7), sperma (9), liquido seminale (1) y ovociti (41), ovuli (4). El término adozione, en cambio, no se usa en el discurso original italiano sobre RA (solamente 3 ocurrencias donde se usa en la colocación ‘adoptar tecnologías/técnicas) y se usa en IT_PMA como calco del español (cf. Figura 11).
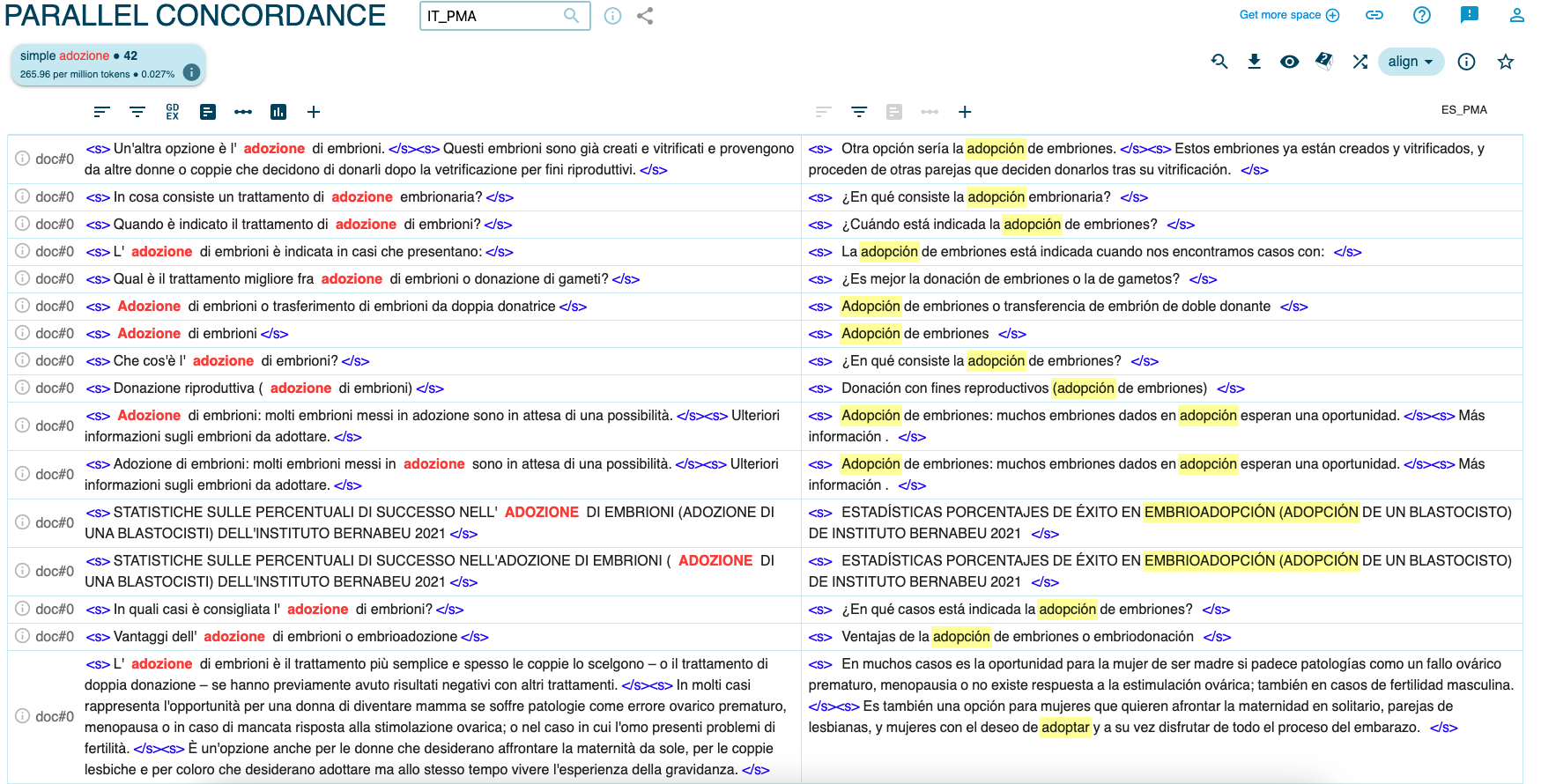
Figura 11. Adozione en el corpus paralelo
Menos interesantes para la finalidad del presente estudio son palabras clave como puntura follicolare (51), en segunda posición (cf. Figura 9), o riproduzione umana assistita (19), tecnica di riproduzione umana (17), que son calcos del español puesto que en italiano se prefiere hablar de pick-up ovocitario (43 PMA_ITALIA) y de procreazione medicalmente assistita (97 PMA_ITALIA) sin empleo del adjetivo humano, empleado en el título de la Ley 14/2006, de 26 de mayo. Como se ha señalado, estos casos revelan un exceso de literalidad que también puede deberse al empleo de motores de traducción automática.
Los ejemplos presentados revelan cómo la ausencia de una terminología estandarizada/oficial disponible en italiano —consecuencia de la ausencia de una reglamentación del tema a nivel legislativo— y la necesidad imprescindible de traducir estos conceptos al italiano para aquellas personas que quieran someterse a estos tratamientos en España contribuyen a la implantación de un discurso traducido que bien podría configurarse como ‘tercer espacio’ (Bhabha, 1994), a saber, un espacio indeterminado de indecisión cultural en el que el significado se produce siguiendo principios de negociación e hibridez. Esto plantea importantes retos traductológicos, cuyas huellas se pueden encontrar también en nuestro corpus, como se adelantaba en §2. El corpus paralelo revela supresiones y adaptaciones/localizaciones del contenido de las páginas web de los sitios españoles.
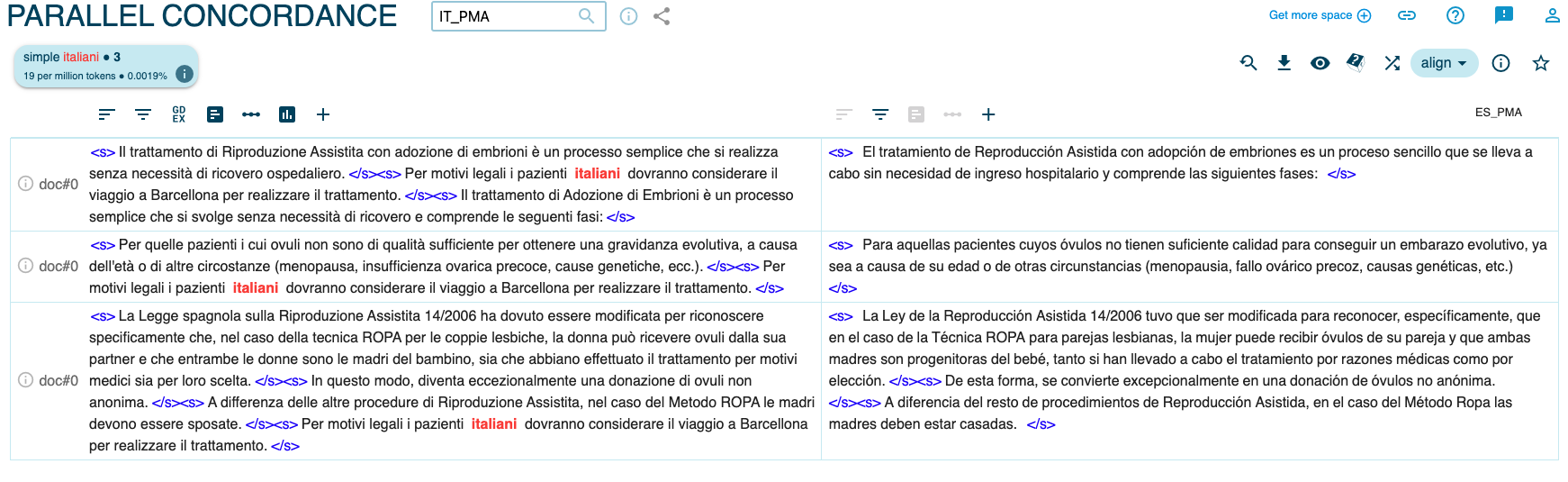
Figura 12. Ejemplo de localización en el corpus paralelo (i pazienti italiani)
Como se desprende de la Figura 12, en las páginas italianas se añade una advertencia relativa a las técnicas mencionadas anteriormente (embrioadopción y método ROPA): ‘Per motivi legali i pazienti italiani dovranno considerare il viaggio a Barcellona per realizzare il trattamento’ (Por razones legales, los pacientes italianos tendrán que plantearse viajar a Barcelona para someterse al tratamiento). Se trata de una solución traductora que intenta dar cuenta del vacío legislativo existente en Italia, país que no prevé dichas técnicas, y que serán objeto de futuro análisis del corpus IT_PMA_ext (cf. §2, Tabla 1). En efecto, un análisis pormenorizado de las asimetrías distribucionales relativas a la frecuencia de determinadas técnicas inexistentes en Italia en los dos corpus de control ES_PMA_ext e IT_PMA_ext bien podría revelar casos de supresión o adaptación/localización del contenido para un público italiano. Basta con pensar en el término ROPA que ocurre con una frecuencia de 237 en ES_PMA_ext y 99 en ES_PMA, lo cual apuntaría a eliminaciones del término en la fase de traducción/localización de las páginas web españolas al italiano. Lo mismo ocurre con los ejemplos ya mencionados maternidad en solitario (26 ES_PMA_ext vs. 14 ES_PMA) y mujeres/madres solteras (33 ES_PMA_ext vs. 26 ES_PMA).
Otro ejemplo paradigmático es el texto que se añade en la traducción al italiano de algunas páginas web de unos centros españoles que mencionan la imposibilidad para las mujeres solteras o las parejas homosexuales de recurrir a la donación de gametos o que proporcionan información útil para pacientes procedentes de Italia cf. Figura 13 (Italia: 18 en IT_PMA_ext y 0 en IT_PMA).
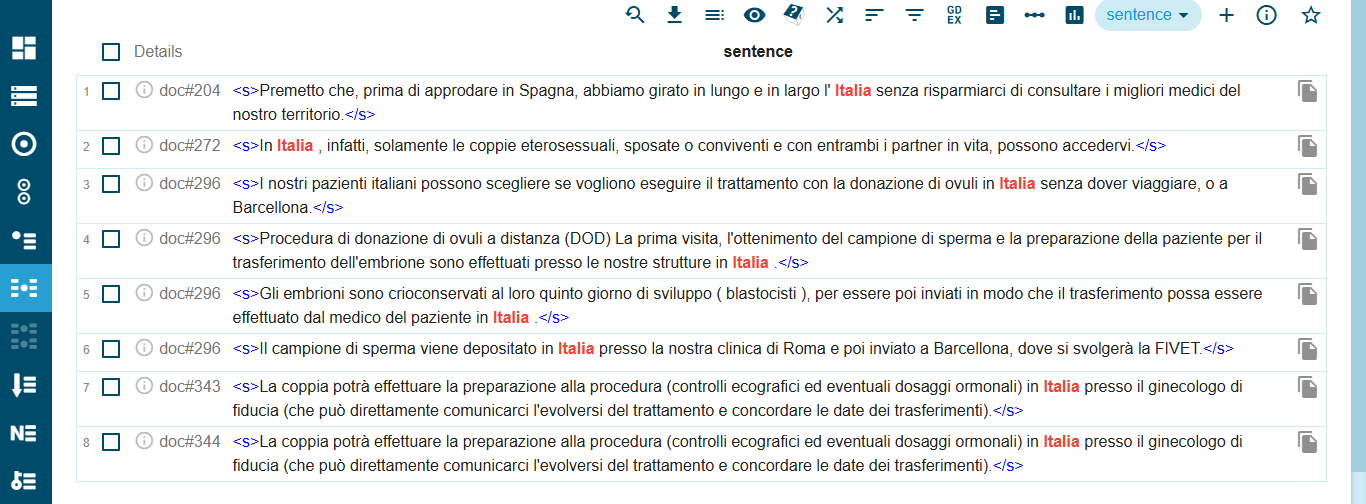
Figura 13. Ejemplo de localización en el corpus paralelo (in Italia)
Estos segmentos se han excluido automáticamente del subcorpus IT_PMA puesto que no tienen sus segmentos equivalentes en ES_PMA y no cumplen por tanto el requisito para la creación de corpus paralelos.
Finalmente, como afirma Malamatidou (2016), la traducción es inevitablemente un sitio de contacto lingüístico que produce la imitación de un código lingüístico (code-copying continuum), que va más allá de la mera interferencia/transferencia (cf. Corpas Pastor, 2008, pp. 199–200). Algunas traducciones literales o calcos que abundan en el corpus traducido pueden tener una importante función discursiva: normalizar el discurso sobre nuevas maternidades y nuevas concepciones de la familia fruto de replanteamientos de los derechos sexuales y reproductivos. Como se demuestra en §4.4, la traducción puede desempeñar un papel fundamental en esta operación de normalización discursiva.
4.4 La traducción como factor de normalización discursiva
La presencia masiva en la Red de traducciones al italiano de algunas de las técnicas objeto de análisis en §4.1 —procedentes de sitios web de clínicas españolas traducidos al italiano, como en el caso de nuestro corpus de estudio— repercute significativamente en la visibilidad de ciertos procedimientos, como se puede apreciar en las Figuras 14 y 15, que capturan simples búsquedas de frecuencias en Google.
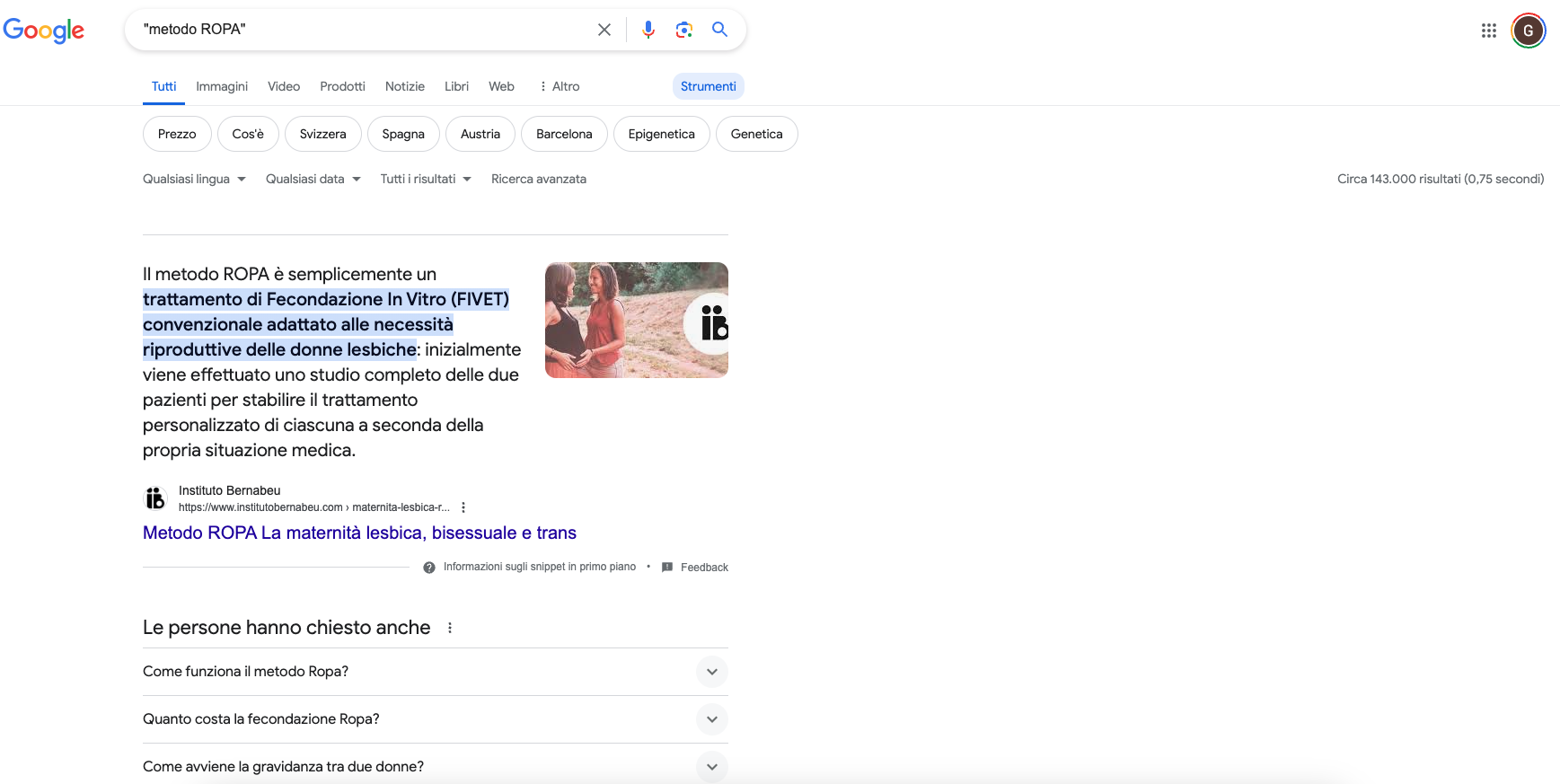
Figura 14. ‘Metodo ROPA’ en Google (143.000 resultados)
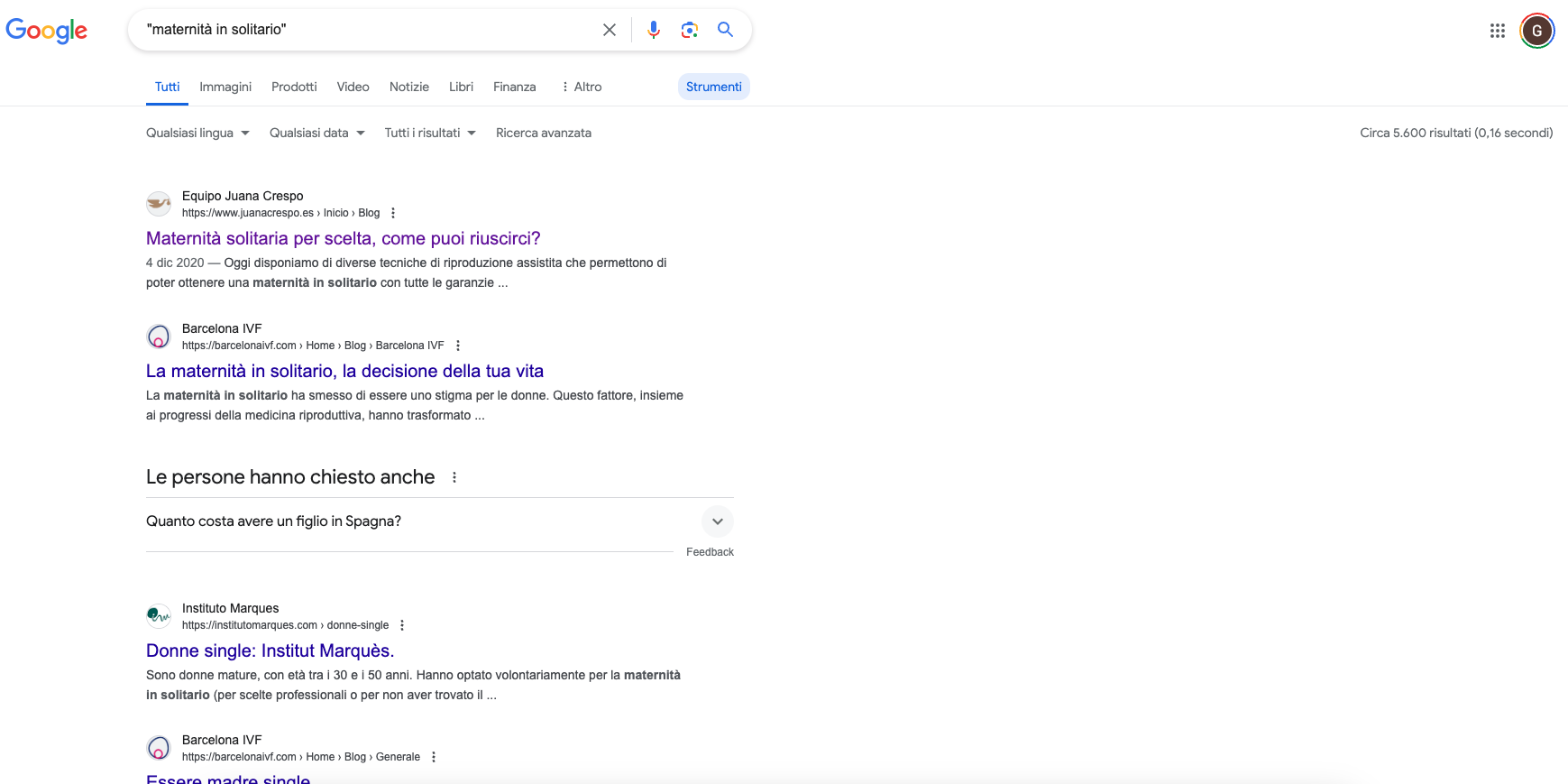
Figura 15. ‘Maternità in solitario’ en Google (5.600 resultados)
Esto puede tener importantes implicaciones para la traducción automática (y la inteligencia artificial en general) y para la didáctica de la traducción biosanitaria.
Por lo que se refiere a las consecuencias negativas, a nivel de traducción automática, la disponibilidad de textos traducidos almacenados en la Red facilita la traducción de segmentos ya traducidos en los sitios web españoles. Es más, muchas veces estas mismas páginas pueden ser productos de traducción automática, lo que crea un círculo vicioso que reproduce errores de traducción (cf. Rico Pérez y Martínez Pleguezuelos, 2025, p. 255) y soluciones traductoras que poco se ajustan a las convenciones discursivas del género paralelo italiano. En cuanto a la didáctica de la traducción especializada, la presencia masiva en la Red de este discurso traducido puede crear dificultades para el alumnado que no disponga de corpus de referencias como PMA_ITALIA y que se deje guiar, como muchas veces ocurre, por la frecuencia absoluta de una determinada expresión en Google o por las soluciones proporcionadas por motores de traducción automática como Google Translate o DeepL. Así, puede pasar que el alumnado considere como solución aceptable el calco puntura follicolare (‘punción folicular’) en vez de ‘pick-up’, ejemplo mencionado en §4.3, porque el término se encuentra con una elevada frecuencia en los cibergéneros o donante en vez de donatore, ejemplo mencionado en §4.1.
Sirva de ejemplo la traducción automática de este breve fragmento extraído de un caso clínico publicado por la Sociedad Española de Medicina de Laboratorio18 y traducido por DeepL (cf. Figura 16), cuya traducción no está disponible en la web y no forma parte del corpus paralelo objeto de estudio.
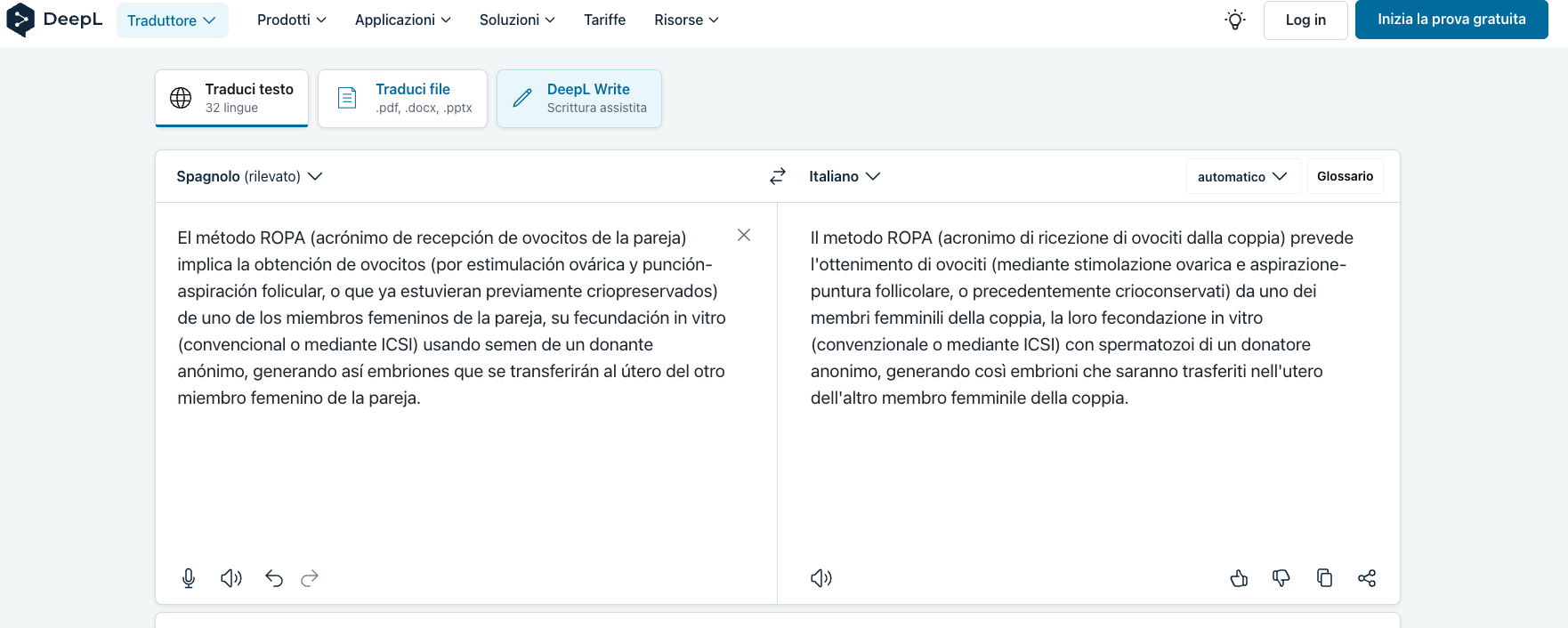
Figura 16. Fragmento de un caso clínico traducido al italiano por DeepL
El texto describe el ya mencionado método ROPA y se basa totalmente en soluciones traductoras empleadas en las páginas traducidas de nuestro corpus paralelo (p.ej., puntura follicolare, crioconservati, membro femminile della coppia, etc.). Si determinadas expresiones entran a formar parte del vocabulario especializado italiano es también gracias (o por culpa, en el caso específico de la Figura 16) de la traducción automática. Cabe preguntarse hasta qué punto este italiano traducido se cuela en el vocabulario de la reproducción asistida y qué impacto tiene en la introducción de posibles neologismos en la lengua italiana y en su disponibilidad léxica.
Por otro lado, esta abundancia de material traducido puede tener consecuencias positivas porque contribuye a la visibilización y normalización de nuevos discursos sobre la maternidad. La posibilidad de recurrir a técnicas de reproducción asistida en otros países y la presencia capilar de material informativo sobre estos tipos de procedimientos pueden contribuir a producir ciertos cambios ideológicos en la sociedad italiana, abriendo el horizonte cognitivo de muchos/as ciudadanos/as italianos/as.
5. Consideraciones finales
El análisis realizado en este trabajo, que no tiene pretensión alguna de exhaustividad, ha permitido confirmar algunas tendencias relativas a la traducción (al italiano) del discurso (en español) sobre reproducción asistida. Los resultados obtenidos del análisis lingüístico guiado por corpus sobre sexismo (§4.1 y §4.2) han puesto de manifiesto que la traducción puede revelarse un medio que amplifica el sexismo lingüístico y por tanto necesita la debida atención. La lengua española parece tener más conciencia de género que la italiana, si bien en ambas lenguas prima el uso del masculino genérico. Sin embargo, desde la perspectiva traductológica, no es cierto que se trate de sexismo lingüístico relacionado con traductores/as humanos/as que eligen conscientemente traducir el femenino español como masculino italiano ya que, como se ha observado, también puede asociarse al uso de la traducción automática y su ‘male bias’. Lo que queda claro es que el acto de traducir implica una toma de decisiones que puede influir en la cultura meta y en su uso de la lengua, por lo tanto, sería conveniente empezar a traducir con conciencia de género y a entrenar los sistemas automáticos de traducción para que sepan identificar y traducir distintos géneros. Como bien señalan Rico Pérez y Martínez Pleguezuelos (2025, p. 255), la traducción automática se basa en la extracción de segmentos traducidos presentes en corpus de millones de palabras, que se usan para entrenar los modelos de inteligencia artificial para que imiten el comportamiento humano. Esto quiere decir que la calidad de las traducciones generadas automáticamente depende de la calidad de los datos disponibles en la Red y utilizados para el entrenamiento (cf. el círculo vicioso citado en §4.4). La traducción automática se basa en textos que se repiten y circulan en la sociedad, con lo cual el sesgo de género es casi inevitable. Como se trata de programas que se utilizan cada vez más y cuyos productos finales no siempre se revisan, pueden contribuir a la propagación y difusión (conscientes o inconscientes) de usos lingüísticos sexistas y discriminatorios.
El análisis basado en corpus presentado en §4.3 ha permitido identificar, mediante la técnica de las palabras clave (Keywords) y por tanto de forma semiautomática, las asimetrías existentes entre España e Italia a la hora de acceder a la reproducción médicamente asistida, poniendo de relieve aquellas técnicas que no están permitidas en Italia y cuya conceptualización pasa por una inevitable transferencia y negociación traductora. El análisis también ha revelado las huellas del contacto lingüístico que se manifiestan tanto a través de calcos o traducciones literales (desajustes de las convenciones discursivas evidentes en la comparación con corpus de textos originales) como con neologismos que pueden desempeñar una importante función normalizadora, como en el caso de los ejemplos esbozados en §4.4. El discurso traducido sobre reproducción asistida se caracteriza por una hibridación y contaminación, que pueden depender del empleo generalizado de la traducción automática no revisada y empleada de forma inapropiada. La presencia masiva de estos textos en línea influye en la disponibilidad y circulación de un vocabulario contaminado sobre todo en relación a técnicas no admitidas en Italia. En este escenario, la traducción puede amplificar el sexismo lingüístico y discursivo porque puede contribuir a transmitir ideologías estereotipadas que difícilmente se pueden reformular, si son productos de traducción automática. Para que esto no ocurra, deberíamos empezar a cuidar el uso de la lengua y usar con conciencia crítica las palabras que empleamos para describir el mundo y que son objeto de traducción a su vez. Es a través de la lengua y de la traducción que moldeamos la sociedad. Y esto es aún más importante en un escenario de alto riesgo como el caso de las clínicas de fertilidad objeto de investigación en este trabajo, caracterizado por factores como la credibilidad de la institución y la protección del consumidor/usuario que necesitan una meticulosa y razonada gestión del riesgo en traducción (cf. Pym, 2025).
El presente trabajo representa solamente un primer paso hacia investigaciones de mayor envergadura que se centren en la representación discursiva de las nuevas familias también a través de la multimodalidad (véanse, por ejemplo, Balirano, Mackenzie, Zottola, 2024). En efecto, las páginas web que componen nuestros corpus constituyen un repertorio fascinante de imágenes y vídeos que merecerían una profundización en estudios futuros, puesto que, no solamente las palabras, sino también las imágenes, contribuyen a dibujar el imaginario de las personas ‘con sueño de formar familia’ —expresión que se encuentra a menudo en nuestro corpus, donde sueño es una de las palabras clave (29 ES_PMA 29, 151 ES_PMA_ext)— sobre reproducción asistida y, más en general, sobre derechos sexuales y reproductivos.
Agradecimientos/Financiación
Este artículo se enmarca en el proyecto de investigación interdisciplinar “Rights and Prejudice. Linguistic and Legal Implications of Gendered Discourses in Judicial Spaces [GenDJus]” financiado por el Ministerio de la Universidad e Investigación (MUR) y la Unión Europea (programa de financiación Next Generation EU) (Missione 4 "Istruzione e ricerca" — Componente 2 "Dalla ricerca all’impresa" — Investimento 1.1, Avviso Prin 2022 PNRR indetto con Decreto Direttoriale n. 1409 del 14 settembre 2022, Prot. P2022FNH9B — CUP J53D23017220001) [https://gendjus.it/].
Referencias
Baker, M. (1993). Corpus Linguistics and Translation Studies. Implications and Applications. In M. Baker, G. Francis, & E. Tognini-Bonelli (Eds.), Text and Technology: In Honor of John Sinclair (pp. 233–250). Benjamins.
Balirano, G., Mackenzie, J., & Zottola, A. (Eds.). (2024). The Discursive Construction of Contemporary Family Types. Special Issue of de genere. Rivista di studi letterari, postcoloniali e di genere, 1–138.
Baroni, M., & Bernardini, S. (2004). BootCat: Bootstrapping corpora and terms from the web. Proceedings of LREC 2004.
Bengonchea Bartolomé, M. (2015). Lengua y género. Síntesis.
Bhabha, Homi K. (2004 [1994]). The Location of Culture. Routledge.
Bolasco, S. (2013). L’analisi automatica dei testi. Fare ricerca con il text mining. Carocci editore.
Bolasco, S., Morrone, A., & Baiocchi, F. (1999). A Paradigmatic Path for Statistical Content Analysis Using an Integrated Package of Textual Data Treatment. In M. Vichi & O. Opitz (Eds.), Classification and Data Analysis. Theory and Application (pp. 237–246). Springer-Verlag.
Calvi, M. V. (2023). Las lenguas de especialidad. In MV Calvi, C. Bordonaba Zabalza, G. Mapelli, & J. Santos López (Eds.), Las lenguas de especialidad en español. Nueva edición (pp. 19–43). Carocci editore.
Cardinaletti, A. (2005). La traduzione: un caso di attrito linguistico. In A. Cardinaletti, & G. Garzone (eds.) L’italiano delle traduzioni (pp. 59–83). FrancoAngeli.
Carreras i Goicoechea, M., & Zucchini, L. (2011). I generi delle pari opportunità: riflessioni linguistiche sul maschile e il femminile nella normativa nazionale spagnola e italiana. In G. Bazzocchi, & R. Tonin (Eds.), Identidad y género en ámbito hispánico (pp. 127–164). Franco Angeli.
Carreras i Goicoechea, M., & Savoca, M. (2014). Cuestiones de género en la traducción de textos científicos sobre reproducción asistida (RA). Panacea 15 (39), 109–117.
Corpas Pastor, G. (2008). Investigar con corpus en traducción: los retos de un nuevo paradigma. Peter Lang.
Fuentes Arderius, X., Antoja Ribó, F., & Castiñeiras Lacambra MJ. (s.f.). Manual de estilo para la redacción de textos científicos y profesionales. Grupo de Trabajo de Nomenclatura y Traducciones en Español de la Federación Internacional de Química Clínica y Ciencias de Laboratorio Clínico y Comité Científico de la Confederación Latinoamericana de Bioquímica Clínica y Comisión de Terminología y Comité de Publicaciones de la Sociedad Española de Bioquímica Clínica y Patología Molecular.
García Meseguer, Á. (1988). Lenguaje y discriminación sexual. Montesinos.
Jiménez-Crespo, M. A. (2013). Translation and Web Localization. Routledge.
Jiménez-Crespo, M. A. (2023). ‘Translationese’ (and ‘post-editese’?) no more: on importing fuzzy conceptual tools from Translation Studies in MT research. In M. Nurminen et al. (Eds.), Proceedings of the 24th Annual Conference of the European Association for Machine Translation (pp. 261–268). European Association for Machine Translation.
Kilgarriff, A., Rychlý, P., Smrž, P., & Tugwell, D. (2004). The Sketch Engine. Proceedings of the 11th EURALEX International Congress, 105–116.
Laviosa, S. (1998). Core Patterns of Lexical Use in a Comparable Corpus of English Narrative Prose. Meta, XLIII, 4, 1–15.
Laviosa, S. (2012). Corpus linguistics in translation studies. In C. Millán, & F. Bartrina, (Eds.), The Routledge Handbook of Translation Studies (pp. 228–240). Routledge.
Leiva Rojo, J. (2018). Designing and compiling parallel aligned corpora: pitfalls and (some) solutions on the example of a corpus of translated museum texts (English-Spanish). Revista de Lingüística y Lenguas Aplicadas, 13, 59–73.
Machin, D., & Mayr, A. (2023). How to do Critical Discourse Analysis. A Multimodal Introduction. Second Edition. SAGE.
Malamatidou, S. (2016). Understanding translation as a site of language contact: the potential of the code-copying framework as a descriptive mechanism in Translation Studies. Target 28:3, 399–423.
Mapelli, G. (2023). El lenguaje técnico-científico. In MV Calvi, C. Bordonaba Zabalza, G. Mapelli, & J. Santos López (Eds.), Las lenguas de especialidad en español. Nueva edición (pp. 127–152). Carocci editore.
Monzó-Nebot, E., & Tasa-Fuster, V. (Eds.). (2025). Gendered Technology in Translation and Interpreting. Centering Rights in the Development of Language Technology. Routledge.
Ondelli, S., & Viale, M. (2010). L’assetto dell’italiano delle traduzioni in un corpus giornalistico. Aspetti qualitativi e quantitativi. Rivista internazionale di tecnica della traduzione, n. 12, 1–62.
Ondelli, S. (2020). L’italiano delle traduzioni. Carocci.
Pacheco-Baldó, R. M. (2023). Las dimensiones culturales, la hipérbole y el autobombo en páginas web de clínicas de fertilidad en Londres y Madrid. Panace@, vol. XXIV, n. 58, 86–95.
Pym, A. (2025). Risk Management in Translation. Cambridge University Press.
Rico Pérez, C., & Martínez Pleguezuelos, A. J. (2025). Exploring Gender Bias in Machine Translation of Legal Texts. In E. Monzó-Nebot, & V. Tasa-Fuster (Eds.), Gendered Technology in Translation and Interpreting. Centering Rights in the Development of Language Technology (pp. 253–273). Routledge.
Robustelli, C. (2000). Lingua e identità di genere. Studi Italiani di Linguistica Teorica e Applicata, XXIX, 2000, 507–527.
Sabatini, A. (Ed.). (1987). Il sessismo nella lingua italiana, Commissione nazionale per la realizzazione della parità tra uomo e donna, Presidenza del Consiglio dei Ministri, Roma.
Sandrini, P. (2005). Website Localization and Translation. MuTra 2005 – Challenges of Multidimensional Translation: Conference Proceedings, 131–138.
Sandrini, P. (2008). Localization and Translation. LSP Translation Scenarios. Selected Contributions of the EU Marie Curie Conference Vienna 2007, 167–191.
Santamaría Pérez, M.I. (2023). Salud y comunicación: análisis lingüístico de las páginas web sanitarias. El caso de la Reproducción Asistida. In A. Sánchez Fajardo, & C. Vargas Sierra (Eds.), La traducción en la encrucijada interdisciplinar. Temas actuales de traducción especializada, docencia, transcreación y terminología (pp. 341–376). Tirant lo Blanch.
Sapir, E. & Lee Whorf, B. (2017). Linguaggio e relatività. Carassai, M., & Crucianelli, E. (Eds.), Castelvecchi.
Shepherd, M. & Watters, C. (1998). The evolution of Cybergenres. In R. Sprague (Ed.), Proceeding from the XXXI Hawaii International Conference on System Sciences, Los Alamitos: IEEE-Computer Society, 97–109.
Tognini-Bonelli, E. (2001). Corpus linguistics at work. John Benjamins.
Toury, G. (1995). Descriptive Translation Studies and Beyond. John Benjamins.
van Leeuwen, T. (2008). Discourse and Practice: New Tools for Critical Discourse Analysis. Oxford University Press.
Vanmassenhove, E., Hardmeier, C., & Way, A. (2021). Getting Gender Right in Neural Machine Translation. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Process, 3003–3008.
Páginas web
Se indica a continuación el listado completo de las páginas web que forman parte del corpus de estudio (última fecha de consulta: 18/05/25).
PMA_ITALIA (corpus monolingüe original):
Ivi Bari S.R.L. (https://ivitalia.it/centri/bari/)
Prolab Srl (https://www.prolab-pma.it/)
Humanafertilitas (https://humanafertilitas.it/),
Poliambulatorio Privato Day Surgery Next Fertility Gynepro (https://nextfertilitygynepro.it/poliambulatorio/)
MOMO' FertiLIFE (https://www.momofertilife.com/)
pro Andros s.r.l. (https://proandros.it/)
C.B.R. centro di biologia della riproduzione (https://www.cbrpalermo.it/)
Centro Procreazione Assistita "Demetra" (https://centrodemetra.com/)
Futura Diagnostica Medica - Procreazione Medicalmente Assistita S.R.L. (https://futuradiagnosticamedica.it/)
Generalife Milano (https://www.generapma.it/)
Clinica Eugin (https://www.eugin.it/)
Centro di PMA dott. Sannino Ferdinando (https://www.visprocreandi.it/)
Centro fecondazione assistita "Andrea Grimaldi" (https://www.andreagrimaldi.com/hub/centro-fertilita/)
Global Life Srl - Centro fecondazione assistita (https://www.centrofecondazioneassistita.com/)
Megaride Fertility Network - Casa di cura Villa Angela (https://megaridefertility.com/)
PROVITA (https://centroprovita.web-pages.it/)
Centro PMA Valdera (https://www.pmavaldera.it/trattamenti/prestazioni-pma-9/elenco/)
GATJC - Gioia Tauro (https://www.gatjc.com/)
Centro Biofertility (https://www.centroinfertilita.it/)
RAPRUI S.R.L. (https://raprui.com/)
Extra Omnes - Medicina e salute riproduttiva (https://www.extra-omnes.it/)
A.G.I. Medica PMA (https://www.agimedica.it/)
C. M. R. Centro di medicina riproduttiva e procreazione assistita (https://www.infertilitadicoppia.com/)
Centro "TETHYS" (https://tethys-pma.it/)
ES_PMA / IT_PMA (corpus bilingüe paralelo):
Clinicas Ginemed S.L.P. (https://www.ginemed.es/)
MAR & GEN (https://www.clinicamargen.com/es/)
Instituto Avantia de Fertilidad (https://www.avantiafertilidad.com/it/)
Laboratorio de Reproducción Centro Gutenberg S.L. (https://urecentrogutenberg.es/)
Clínicas Rincón Dental-Instituto De Fertilidad (https://www.rinconfertilidad.com/)
Oy Fertia Costa del Sol S.L. (https://clinicafertia.com/)
Clinica Ergo (https://clinicaergo.com/it/)
Instituto Bernabeu Palma De Mallorca (https://www.institutobernabeu.com/)
Centro de Asistencia a la Reproducción Humana de Canarias (https://www.fivap.com/)
Consulta de ginecología y reproducción asistida IGIN (https://www.institutoigin.com/)
BCNIVF (https://barcelonaivf.com/es/)
Centre ginecologic Santiago Dexeus (https://www.dexeus.com/fertility/)
Centro de reproducción asistida Clínica Sagrada Familia SL (https://www.cra.barcelona/)
GINEFIV (https://www.ginefiv.com/)
Instituto de reproducción CEFER (https://www.institutocefer.com/)
FERTILAB-Institut Catala de Fertilitat (https://fertilab.com/)
Reproclinic (https://reproclinic.com/es)
Ovoclinic Ceuta (https://ovoclinic.net/)
IVF Spain Madrid S.L. (https://www.ivf-spain.com/)
Amnios In Vitro Project (https://amnios.es/)
Vida Fertility Institute SL (https://vidafertility.com/)
Fertility Benidorm SL (https://fertilitybenidorm.com/)
Next Fertility Valencia (https://nextfertility.es/)
Instituto FIVIR (https://www.fivir.es/)
Equipo Juana Crespo (https://www.juanacrespo.es/)
Centro Fertilidad Bilbao (https://centrofertilidad.com/)
Centro médico Manzanera (https://www.centromedicomanzanera.com/)
Hospital IMED Elche (https://www.vitafertilidad.com/)
Institut Marques (https://institutomarques.com/)
Declaración de disponibilidad de datos
Todos los datos generados y analizados en el marco de la presente investigación se incluyen en este mismo artículo. Las personas interesadas en obtener datos adicionales pueden contactar con los autores.
Este artículo es el resultado de una intensa colaboración de los dos autores. Por razones de reconocimiento académico, se señala que Gianluca Pontrandolfo es autor de los apartados §1, §4.2, §4.3 y §4.4 y Chiara Sarni es autora de los apartados §2, §3 y §4.1. Las conclusiones (§5) se han redactado juntamente.↩︎
https://orcid.org/0000-0002-9128-0321, gpontrandolfo@units.it↩︎
https://orcid.org/0009-0000-8439-6708, chiara.sarni@units.it↩︎
https://www.europapress.es/turismo/nacional/noticia-espana-meca-turismo-reproductivo-ue-20230331132533.html (consultado el 29/06/2024).↩︎
https://www.trovanorme.salute.gov.it/norme/dettaglioAtto?id=4538 / https://www.boe.es/buscar/act.php?id=BOE-A-2006-9292 (consultado el 29/06/24).↩︎
https://cnrha.sanidad.gob.es/registros/busqueda.htm (consultado el 25/05/2024).↩︎
https://www.iss.it/rpma (consultado el 25/05/2024).↩︎
Es preciso indicar, a este respecto, que tanto en la Tabla 3 como en la Tabla 4 solo se han incluido los tiempos y modos verbales que tenían una frecuencia superior a cero en al menos uno de los tres corpus.↩︎
El vocabulario italiano Treccani solo la define como un sustantivo de uso jurídico https://www.treccani.it/vocabolario/donare/ (consultado el 24/06/2024).↩︎
Por lo que concierne a las palabras que aparecen en las figuras mencionadas, solo se producen casos de cambio del femenino al masculino: doctora (1) > medico (1), doctoras (2) > medici (2), ginecóloga (2) > ginecologo (1), ginecólogas (2) > ginecologi (2), psicóloga (13) > psicologo (4).↩︎
Véanse, por ejemplo, las siguientes páginas: https://tinyurl.com/45z8za4m, https://tinyurl.com/55d9aa24 (consultados el 18/05/25).↩︎
Véanse, por ejemplo, las siguientes páginas: https://tinyurl.com/2n93fu49, https://tinyurl.com/ynsm3rpu (consultados el 18/05/25).↩︎
Véase, por ejemplo, el siguiente caso: texto origen en ES (https://tinyurl.com/2y56x6cj) vs. texto meta en IT (https://tinyurl.com/3jc7vzwb) (consultados el 18/05/25).↩︎
Véase, por ejemplo, el siguiente caso: texto origen en ES (https://tinyurl.com/ycka2kkz) vs. texto meta en IT (https://tinyurl.com/yzwtjyvn) (consultados el 18/05/25).↩︎
Véase, por ejemplo, el siguiente caso: texto origen en ES (https://tinyurl.com/ysn3ap5s) vs. texto meta en IT (https://tinyurl.com/yaa88ujj) (consultados el 18/05/25).↩︎
Véase, por ejemplo, el siguiente caso: texto origen en ES (https://tinyurl.com/2s3awu6w) vs. texto meta en IT (https://tinyurl.com/yu8kpt6a) (consultados el 18/05/25).↩︎
Véase, por ejemplo, el siguiente caso: texto origen en ES (https://tinyurl.com/56fh4m3p) vs. texto meta en IT (https://tinyurl.com/32tjp9vr) (consultados el 18/05/25).↩︎
https://www.seqc.es/download/tema/14/4424/6279335/245834/cms/tema-1-caso-clinico.pdf/ (consultado el 29/06/24).↩︎